Zero trust server security sounds grand until you’re staring at a pager at 2:11 a.m. with a blast of failed SSH attempts and a CPU graph that looks like a picket fence. That was me last spring. A forgotten jump box, a stale local admin, and a permissive security group invited trouble. We got lucky—no data moved, the doors slammed shut, and the lessons stuck. Since that night, I’ve been ruthless about small, boring controls that add up to a fortress. What follows is the exact playbook I reach for now, tuned for 2025 realities and written for folks who actually have to run this stuff at 3 a.m.
Here’s the vibe: honest tactics, minimal heroics, and lots of receipts. You’ll see how zero trust server security applies to identity, the network, TLS, runtime defenses, backups, and observability—plus the checklists I wish I’d had earlier. If you’re a developer turned reluctant admin or an SRE who lives in terminals, this is meant to be copy‑paste friendly but opinionated enough to steer you away from rabbit holes.

What “Zero Trust Server Security” Actually Means
The idea isn’t complicated: don’t trust the network, don’t trust identities by default, and don’t trust workloads just because they’re “inside.” Authenticate, authorize, and encrypt every hop. Log everything you can stomach. Treat configuration as code so you can prove what changed and when. In practice, zero trust server security looks like short‑lived credentials; strong device identity; micro‑segments with mTLS; minimal outbound access; runtime sensors that spot odd behavior; and playbooks that kick in before your coffee cools.
Notice what’s not on that list: magic boxes, one‑click “harden me” scripts, and flags that claim to solve everything. We’re gonna be pragmatic and stack small wins. You’ll trade a bit of setup time for huge gains in blast‑radius control and post‑incident confidence.
Keyword Heat Map: What’s Hot in 2025 (and Why You Should Care)
I keep seeing the same phrases come up in postmortems, RFPs, and forum threads. Here’s the translation layer you can use with your team:
- CNAPP / CWPP / CSPM: Cloud platforms that scan config, images, and runtime. For servers, look for least‑privilege policies and live process visibility.
- eBPF runtime security: Kernel‑level hooks that observe (and sometimes gate) syscalls. Gold for spotting weird lateral moves without agents that chew RAM.
- Passkeys / FIDO2 for SSH: Hardware‑backed keys feel like cheating—in a good way. No passwords for attackers to spray or phish.
- mTLS everywhere: Service‑to‑service identity with short certs. Microsegmentation’s best friend.
- SBOM + signed artifacts: Know what’s inside your software and prove it hasn’t been swapped. Cosign/Sigstore are the usual suspects.
- TLS 1.3 + ECH + HTTP/3: Modern crypto and transport for the public edge; just be deliberate—visibility shifts when you encrypt more metadata.
- XDR / SIEM convergence: Unified signals from hosts, identity, and the network. Less swivel‑chair, faster answers.
Baseline Hardening: The Boring Bits That Save You
Before you buy a shiny tool, tighten the bolts. The goal: predictable builds you can re‑create in an hour. That’s the boring superpower behind zero trust server security.
Linux quick wins
# 1) Update + minimal packages sudo apt update && sudo apt -y upgrade sudo apt -y install unattended-upgrades && sudo dpkg-reconfigure -plow unattended-upgrades
2) Create a non-root admin & lock root
sudo adduser ops --disabled-password
sudo usermod -aG sudo ops
sudo passwd -l root
3) SSH sane defaults
sudo cp /etc/ssh/sshd_config /etc/ssh/sshd_config.bak
sudo tee /etc/ssh/sshd_config <<'EOF'
Port 22
PermitRootLogin no
PasswordAuthentication no
KbdInteractiveAuthentication no
PubkeyAuthentication yes
AuthenticationMethods publickey
ClientAliveInterval 120
ClientAliveCountMax 2
AllowUsers ops
EOF
sudo systemctl restart sshd
4) Firewall (UFW or nftables)
sudo apt -y install ufw && sudo ufw default deny incoming
sudo ufw default allow outgoing
sudo ufw allow 22/tcp
sudo ufw enable
5) Journald persist + log rotate
sudo mkdir -p /var/log/journal && sudo systemd-tmpfiles --create --prefix /var/log/journal
sudo systemctl restart systemd-journald
Windows Server quick wins
# 1) Update + basics Install-PackageProvider -Name NuGet -MinimumVersion 2.8.5.201 -Force Install-Module PSWindowsUpdate -Force Get-WindowsUpdate -Install -AcceptAll -AutoReboot
2) Local admin: create, rotate, log
net user opsStrongPwd /add
net localgroup Administrators opsStrongPwd /add
3) RDP + WinRM hygiene
Set-ItemProperty "HKLM:\System\CurrentControlSet\Control\Terminal Server" -Name "fDenyTSConnections" -Value 1
Disable-NetFirewallRule -DisplayGroup "Remote Desktop" # keep off unless truly needed
Set-Item WSMan:\localhost\Service\Auth\Basic -Value $false
Set-Item WSMan:\localhost\Service\AllowUnencrypted -Value $false
4) Windows Defender + ASR rules
Set-MpPreference -DisableRealtimeMonitoring $false
Set-MpPreference -MAPSReporting Advanced
Add-MpPreference -AttackSurfaceReductionRules_Ids D4F940AB-401B-4EFC-AADC-AD5F3C50688A -AttackSurfaceReductionRules_Actions Enabled
These aren’t glamorous. They’re the floor. From here, we layer identity, network, TLS, runtime, and recovery until the system feels annoyingly resilient.
Identity First: Passwordless SSH, Short‑Lived Certs, and Just‑in‑Time Access
If I could pick one lever to pull for zero trust server security, it’d be identity. Kill passwords. Prefer hardware‑backed keys. Issue short‑lived certificates and expire everything quickly. For Linux, OpenSSH has supported FIDO/U2F since 8.2, which means SSH keys can live on a hardware token. Pair that with an SSH CA so you can revoke centrally and rotate without the spreadsheet drama.
Generate a FIDO2 SSH key
ssh-keygen -t ed25519-sk -O resident -O verify-required -C "ops@prod" # Touch your security key when prompted ssh-add -K ~/.ssh/id_ed25519_sk Wire an SSH Certificate Authority (CA)
# CA private key (offline if possible) ssh-keygen -f /etc/ssh/ssh_ca -t ed25519 -C "ssh-ca"
Sign a user key (valid 8 hours, force command/logging if needed)
ssh-keygen -s /etc/ssh/ssh_ca -I ops-08h -n ops -V +8h ~/.ssh/id_ed25519_sk.pub
On servers, trust the CA and ban raw keys
echo "TrustedUserCAKeys /etc/ssh/ca.pub" | sudo tee -a /etc/ssh/sshd_config
echo "PubkeyAuthentication yes" | sudo tee -a /etc/ssh/sshd_config
echo "AuthorizedKeysFile none" | sudo tee -a /etc/ssh/sshd_config
sudo systemctl restart sshd
For Windows, look at device‑bound credentials, Azure AD conditional access, and JIT admin via PAM. Short sessions, heavy logging, and fast revocation. If a laptop walks away, your blast radius should be “one session,” not “the kingdom.”
Network: Microsegmentation and mTLS Without the Tears
Flat networks are comfy for attackers. Split them. Labels and intents beat IP whitelists you’ll forget to update. For small environments, nftables or UFW rules plus WireGuard tunnels go a long way. At scale, you’ll flirt with service meshes or eBPF‑powered policy (Cilium/Calico). The trick is to keep rules easy to read and tie them to identities instead of snowflake IPs. That’s where zero trust server security really pays off.
nftables mini‑policy
sudo nft add table inet filter sudo nft add chain inet filter input { type filter hook input priority 0 \; } sudo nft add rule inet filter input ct state established,related accept sudo nft add rule inet filter input iif lo accept sudo nft add rule inet filter input tcp dport {22,443} accept sudo nft add rule inet filter input ip saddr 10.0.10.0/24 tcp dport 5432 accept # app->db sudo nft add rule inet filter input counter drop WireGuard for service‑to‑service mTLS
# On each peer wg genkey | tee privatekey | wg pubkey > publickey # Configure /etc/wireguard/wg0.conf with peers and AllowedIPs sudo systemctl enable --now wg-quick@wg0 Keep east‑west flows boring and explicit. Pull DNS, NTP, and package mirrors through a known egress and log them. When in doubt, block outbound and add allow‑lists as you discover needs. Your future self will say “thank you” out loud.

TLS at the Edge: TLS 1.3, OCSP Stapling, HTTP/3, and ECH
Strong edge crypto is table stakes now. Enforce modern ciphers, turn on OCSP stapling, and adopt HTTP/3 where it improves tail latency. If you run behind a CDN, you’ll see more talk about Encrypted Client Hello (ECH)—a move that hides the requested hostname during TLS handshake. It’s privacy‑forward, which is good, but it also shifts what your middleboxes can see. Build monitoring at the endpoints and in your apps, not just the wire. That’s still zero trust server security, just at the protocol layer.
Sample Nginx TLS 1.3 config
server { listen 443 ssl http2; http2_max_field_size 16k; http2_max_header_size 32k;
ssl_certificate /etc/ssl/certs/fullchain.pem;
ssl_certificate_key /etc/ssl/private/privkey.pem;
ssl_protocols TLSv1.3;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 1d;
ssl_stapling on;
ssl_stapling_verify on;
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains" always;
location / {
proxy_pass http://app
;
}
}
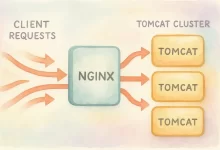
If you’re deep in the Java world, load balancing and TLS offload at Nginx can simplify life. We covered the operational angles in our Nginx Tomcat Load Balancing guide—use it to centralize TLS and keep app servers focused on business logic.
Secrets and Keys: Treat Them Like Live Ammo
Secrets aren’t “files,” they’re liabilities. Don’t ship them in images. Don’t leave them as environment variables forever. Use a vault, bind secrets to identities, and limit scope with policies. Rotate often. If a secret leaks, your logs should show what it could reach and when it was last used.
Vault‑style secret retrieval with short leases
# Pseudo flow role="api-writer" token=$(vault write -field=token auth/jwt/login role=$role jwt=$OIDC_TOKEN) db_creds=$(VAULT_TOKEN=$token vault read -format=json db/creds/$role) export DB_USER=$(echo $db_creds | jq -r .data.username) export DB_PASS=$(echo $db_creds | jq -r .data.password) # Lease expires in minutes, not months Encrypt at rest, sure—but assume a host can be compromised and ask: “What can an attacker do in five minutes with this secret?” That question trims scopes and shortens lifetimes in a way policies never will.
Runtime Defense: Signals, Not Hunches
Once identity and network are tight, runtime is where you catch “unknown unknowns.” Process graphs, syscall patterns, and filesystem touches tell a story. Even basic audit rules spot clumsy privilege escalations. Tie detections to the attack lifecycle so responders know what to do next.

auditd starter rules for Linux
# Track attempts to modify shadow/passwd -w /etc/shadow -p wa -k identity -w /etc/passwd -p wa -k identity
Watch sudoers and SSHD config
-w /etc/sudoers -p wa -k priv_esc
-w /etc/ssh/sshd_config -p wa -k sshd
Track kernel module loading
-w /sbin/insmod -p x -k kernel
-w /sbin/modprobe -p x -k kernel
Sysmon for Linux (coarse but helpful)
# Install sudo apt -y install sysmonforlinux sudo sysmon -accepteula -i sysmon-config.xml Map alerts to tactics (lateral movement, persistence, credential access) so your on‑call knows whether to isolate a host, rotate secrets, or start an egress hunt. That’s how zero trust server security turns into fast, sane response instead of panic.
Patch Like a Pro: SBOMs, Signed Artifacts, Kernel Live Patching
Patching is less terrifying when you know what you’re running and can roll back cleanly. Generate an SBOM for each build, sign the artifacts, and verify at deploy. Push urgent fixes with live patching where available and take your time on the rest. The key is trust you can show with logs and signatures.
Generate and sign artifacts
# SBOM with Syft syft packages dir:./app -o json > sbom.json
Sign the container image
cosign sign --key registry.example.com/app:2025.08.18
Verify at deploy
cosign verify --key registry.example.com/app:2025.08.18
Unattended updates and live kernel patching
# Ubuntu sudo apt -y install unattended-upgrades sudo dpkg-reconfigure -plow unattended-upgrades
Oracle Ksplice / Canonical Livepatch (example toggle)
sudo snap install canonical-livepatch
sudo canonical-livepatch enable
Yes, you still need maintenance windows. But small, frequent, reversible updates beat giant, sweaty, quarterly marathons every time.
Web Layer Resilience: Rate Limits, WAF/WAAP, and Useful Error Budgets
Most attacks still come in through HTTP. Rate limits and a sane WAF knock out the noisy stuff so you can focus on signal. Log at the edge, sanitize inputs in the app, and stop returning stack traces. If you’re proxying Java stacks, that earlier Nginx Tomcat Load Balancing post shows how to centralize SSL and health checks—less to misconfigure on app nodes.
Basic rate limiting in Nginx
limit_req_zone $binary_remote_addr zone=api:10m rate=10r/s;
server {
location /api/ {
limit_req zone=api burst=20 nodelay;
proxy_pass http://backend
;
}
}
Backups, DR, and Ransomware: Recovery Is a Feature
You don’t have security until you can recover. Immutability is your friend: object‑lock storage, write‑once volumes, and cross‑account copies. Backups that share the same credentials and network path as production aren’t backups—they’re decoys. Bake recovery drills into sprint cycles and document timings. The day everything is on fire is not the day to learn your restore tool’s CLI.
If you’re running MySQL, you’ll like the pragmatic tips in Automated MySQL Backup. Snapshots are great; verified dumps plus binary logs are greater. Tie the recovery steps to specific RPO/RTO goals so leadership understands what “safe” actually means.

Immutable backup checklist
- One daily full + frequent incrementals; retention in tiers (hot, warm, cold).
- Write once (S3 Object Lock / immutable volumes) for at least 7–30 days.
- Separate security boundary for backup credentials and network path.
- Quarterly restore drills with time‑to‑first‑byte and time‑to‑serve documented.
Logging, SIEM, and Detections: From Noise to Narrative
Spending more on logs isn’t the goal; answering questions quickly is. Build a concise pipeline: syslog/journald → collector → queue → cheap store → queries that you actually use. Index less; summarize more; retain raw in cold storage. Create a handful of high‑signal rules tied to user actions, privileged paths, new outbound destinations, and policy violations.
Starter detection ideas
- New process spawning network listeners on odd ports.
- SSH logins from new geos tied to privileged roles.
- Outbound connections to freshly registered domains.
- Binary execution from world‑writable directories.
- Changes to sudoers, sshd_config, PAM.
Containers and Cloud Hosts: CNAPP Without the Buzzword Fatigue
Servers are often containers now, and the same laws apply: identity beats IPs; short‑lived creds beat static tokens; runtime beats guesswork. If your platform team owns Kubernetes, insist on per‑namespace network policies, image signing, admission controls that check SBOMs, and a runtime layer that sees syscalls. Tie alerts to workload labels so responders know which team to wake up.
Admission control sketch
apiVersion: admissionregistration.k8s.io/v1 kind: ValidatingWebhookConfiguration metadata: name: verify-signed-images webhooks: - name: cosign.example.com rules: - operations: ["CREATE","UPDATE"] apiGroups: ["apps"] apiVersions: ["v1"] resources: ["deployments","statefulsets"] failurePolicy: Fail sideEffects: None clientConfig: service: name: signer namespace: security caBundle: <base64pem> Policy as Code: Make the Right Path the Easy Path
When policies live in wikis, they wilt. Put them in code. Rego, Gatekeeper constraints, CloudFormation/SAM guardrails—pick your poison and ship guardrails that fail fast. That’s how zero trust server security turns into something teammates feel instead of just read about.
OPA example: deny wide‑open inbound
package netsec
default allow = false
allow {
input.proto == "tcp"
input.port == 443
input.source in {"10.0.10.0/24","10.0.11.0/24"}
}
Day‑Zero Playbook: Securing a Fresh Box in 48 Hours
This is the exact checklist I use when someone spins up “just one server” as a favor:
- Inventory: Register the host in your CMDB or at least a spreadsheet with owner, purpose, zone, and data sensitivity.
- Identity: Add to your directory; enforce hardware‑backed SSH or device certs; issue 8‑hour user certs.
- Network: Place in a microsegment with default deny; open only the one port you need; wireGuard or mTLS for east‑west.
- TLS: Put a real cert on public endpoints; enforce TLS 1.3; staple OCSP; set HSTS; think about HTTP/3.
- Secrets: Pull from a vault on demand; no secrets in images; short leases; scope narrowly.
- Runtime: Install auditd/Sysmon; set a few high‑signal rules; wire to your SIEM; alert on anomalies.
- Backups: Turn on immutable backups with a different security boundary; run a restore test.
- Patching: Enable unattended updates; pin maintenance windows; sign and verify artifacts.
- Docs & handoff: Two pages: ports, owners, secrets path, runbooks. Save it where the team actually looks.
By the end of Day 2, you’ll feel the click. The host becomes boring in the best way. That’s zero trust server security doing its thing.
Real‑World War Story (Short, Because We’ve All Been There)
One Friday at 5:37 p.m., a junior dev left a debug port open on a staging VM that was, unfortunately, peeking into production. Our guardrails caught a new outbound connection to a domain less than a day old. The SIEM flagged it, our XDR killed the process, and our microsegment rules contained the blast radius. It wasn’t heroics—it was the grind: short certs, mTLS, default‑deny, and three alert rules we cared about. We still did the postmortem, rotated secrets, and shipped a new image with the port welded shut. The best part? No one’s weekend got ruined.
Common Pitfalls (and the Fixes That Stick)
- Over‑permissive outbound: Block first, allow known mirrors and APIs. Log the rest and triage weekly.
- Long‑lived secrets: If it lasts more than a day, it’s a liability. Move to short leases and rotate.
- “Temporary” bastions: They become permanent. Use JIT access and auto‑expire rules.
- Unowned servers: No owner, no deploy. Tag owners and revoke access when people move teams.
- Tool sprawl: One agent per problem, not per vendor. Prefer fewer, deeper integrations.
Reference Config Snippets You Can Paste
Fail2ban jail for SSH
[sshd] enabled = true port = ssh filter = sshd logpath = /var/log/auth.log maxretry = 5 bantime = 1h findtime = 10m Systemd hardening for a custom service
[Service] User=app Group=app ProtectSystem=strict ProtectHome=true PrivateTmp=true NoNewPrivileges=true CapabilityBoundingSet= AmbientCapabilities= ReadWritePaths=/var/lib/app Minimal CSP at the edge
add_header Content-Security-Policy "default-src 'self'; img-src 'self' data:; object-src 'none'; frame-ancestors 'none'; base-uri 'self';" always; Performance and Cost: Keep Security Snappy
Security that’s slow gets bypassed. A few principles keep the lights bright:
- Cache smart: OCSP stapling, DNS, and static assets at the edge buy you headroom.
- Measure: Track p50/p95 latency by route; alert when your security layer adds more than 10–15 ms.
- Batch logs: Ship in bursts; sample verbose traces; retain raw in cold storage.
- Right‑size agents: Avoid RAM‑hungry daemons on tiny VMs; prefer kernel sensors with low overhead.
Further Reading That’s Worth Your Time
Two resources I keep bookmarked: Cloudflare’s deep‑dives on modern TLS (including ECH) and OWASP’s concise cheat sheets for secure engineering. If you’re building detections or explaining attacks to stakeholders, the ATT&CK matrix is a good shared map.
Wrap‑Up: Make the Right Path the Easy Path
If you take one thing from this guide, let it be this: zero trust server security is a habit, not a hero moment. Start with identity, carve the network, enforce TLS, watch runtime, and make recovery muscle memory. Small, repeatable wins turn into weekends you actually enjoy.