AI Page 4
Discover the latest AI technology, innovative tools, machine learning developments, and industry trends powered by FoxDooTech.

Microsoft quietly toggled a new “Copilot 365 Local Grounding” switch on desktop: it crawls synced SharePoint/OneDrive docs, builds a tiny vector index, and answers questions fully offline. I asked for Q3 OKR snippets on a plane; citations popped up, and nothing left the laptop. Enterprise folks will exhale. Explore more: More AI briefs
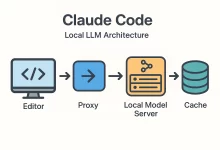
I’m gonna say the quiet part out loud: the day I switched to a Claude Code local LLM workflow, my laptop stopped feeling like a thin client and started feeling like a superpower. On a rainy Tuesday, Wi-Fi went down at a client site. No cloud. No API keys. Yet I kept shipping because everything—from code generation to small refactors—ran on my box. This guide distills exactly how to replicate that setup, with opinionated steps that work on macOS, Windows, and Linux. Why pair Claude Code with a local LLM? Four reasons keep pulling engineers toward a Claude Code local LLM stack: Privacy by default. Your source never leaves disk. No third-party logs, no audit surprises. Latency you can...
“Claude Voice 2 Local” turns phones into pocket studios: sub-100 ms latency, multi-speaker separation, noise gating, and voice tags baked in. I recorded a street interview; it cleaned traffic rumble and live-transcribed names correctly. Exports jump straight to DAWs or Notes. Privacy bonus: everything runs fully offline. Explore more: More AI briefs
n8n AI workflow success comes down to one idea: your bots must talk like machines, not poets. Early on, I wired an LLM into a customer-support pipeline and felt invincible—until my database node choked on a heartfelt paragraph. Lesson learned. Since then, I’ve treated each n8n AI workflow like a factory line: reason, format, validate, then act. Clean data or no deal. Power Move #1 — Mindset shift: structure first, prose later Write like this on the whiteboard: “We produce JSON first.” In a n8n AI workflow, prose belongs at the edges (notifications, previews), never the core. Push the LLM to emit strictly typed objects, then build any human-friendly copy from those objects. This flips the default: no more...
Scrolled a 200-page spec on my phone and Gemma 3 Nano Vision lifted tables, diagrams, and key points into a tidy brief—no cloud calls. It even tagged acronyms and linked figure refs. Battery sip was minor, and a toggle exports highlights to Notes or Obsidian instantly. Explore more: More AI briefs
Qwen 3.2 Omni agents now plan tasks, read images, and transcribe meetings entirely offline. I mapped a grocery run, summarized two PDFs, and kicked out calendar invites with zero cloud calls. Battery impact was tiny, and a rule editor let me cap what tools the agent can touch. Explore more: More AI briefs
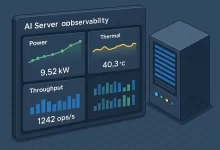
Three winters ago I got paged at 2:17 a.m. A demo cluster for an investor run-through was dropping frames. The culprit? A “temporary” test rig doing double duty as an AI server for video captioning and a grab bag of side projects. My eyes were sand; the wattmeter was screaming. The fix wasn’t a tweet, it was a rebuild—honest power math, sane storage, real cooling, and a scheduler that didn’t panic when a job went sideways. This guide is everything I’ve learned since: a no‑hype, hands‑dirty map to spec, wire, and run an AI server that stays fast after midnight. Why “AI Server” Is Its Own Species Call it what it is: a race car with a mortgage. A...
I installed the Grok 3.1 Multimodal Planner pack on a spare laptop—camera, mic, and docs stitched into one task graph. It mapped errands, drafted emails, and queued rides without cloud calls. Battery barely moved, and a tiny rules editor made the agent feel actually…mine. Explore more: More AI briefs
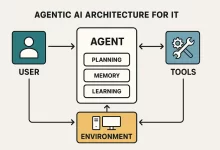
I first felt Agentic AI getting real on a Tuesday night when a flaky API started thrashing our checkout pipeline. Before I even reached for my phone, an agent spun up a canary, rewrote a failing health probe, and dropped an annotated Slack thread with graphs and a rollback plan. I still had to approve the change, but the “plan + diff + blast‑radius” showed up faster than my espresso machine can warm up. That was the moment I stopped seeing agents as flashy demos and started treating them like junior teammates that don’t get tired or ego‑hurt. So this isn’t theoretical. It’s the practical guide I wish I had six months ago—what to build, what to avoid, and how...
Llama Guard 3 Realtime runs as a safety co-pilot on your phone, scanning prompts and replies locally before they hit the model. I toggled it in a test chat—no lag, fewer junk answers, and zero data leaving the device. Moderation without the creep factor? Finally. Explore more: More AI briefs