Edge AI server builds aren’t just “mini data centers.” They’re stubborn little race cars that live in closets, back rooms, or branch offices where the Wi‑Fi is moody and the power budget is a punchline. I’ve shipped, babysat, and occasionally resuscitated these boxes for clients who needed milliseconds, not marketing. What follows is a boots‑on‑the‑ground playbook—hardware picks, power math, cooling gotchas, deployment recipes—for making an edge AI server that answers fast and doesn’t melt when the afternoon sun hits the drywall.
Quick anecdote: one rainy Friday I slid a brand‑new node into a 12U rack wedged behind a printer the size of a hatchback. We fired up a real‑time vision pipeline; everything looked good. Twenty minutes later? Thermal throttle city. The printer’s exhaust was blasting straight into the server intake. We turned the rack ninety degrees, added a simple baffle, and temps dropped thirteen degrees. Not glamorous—just the kind of fix you only learn by standing there with a flashlight and a grumpy store manager. That’s the energy of this guide.
1) Why an Edge AI Server Instead of “Just Use the Cloud”
Latency, privacy, and cost predictability. Inference that has to feel instant—think checkout cameras, kiosk speech, assistive overlays—dies a little every time you cross the public internet. Legal teams also sleep better when the raw pixels or transcripts never leave the building. And when workloads run every waking hour, egress plus per‑token charges can beat the old‑school capex of a box in a closet. I’m not anti‑cloud. I’m pro‑physics and pro‑budget.
2) Core Principles That Keep You Sane
- Balance before bling: Buy lanes, memory channels, and NVMe IOPS that match the GPUs you’re feeding.
- Measure the p99: Peaks trip breakers and throttle fans; design to the worst five minutes, not the average hour.
- Keep it boring where it counts: LTS kernels, pinned driver/toolkit versions, repeatable images, and a quiet scheduler.
- Instrument everything: If you can’t see it, it will fail at 5 p.m. on a holiday weekend.
3) Edge AI Server Fundamentals: Picking a Platform That Won’t Fight You
Start with your form factor: short‑depth rack or tower? For tiny branches, a shallow 12U fits well, but watch PCIe riser fitment. CPU sockets with generous PCIe lanes (and plenty of memory channels) reduce weird topology bottlenecks. Aim for 128–256 GB RAM for lightweight models; double it if you’re juggling big tokenizers, vector stores, and video ingest on the host.
- PCIe layout: Favor x16 lanes per GPU where possible, or x8 Gen4 minimum on inference‑first cards. Avoid crossing CPU sockets unless NUMA is mapped with intent.
- NVMe plan: Tier 0 scratch (short‑lived), Tier 1 primary (weights/datasets), Tier 2 bulk (archives/checkpoints). Give logs a home that doesn’t fight your models.
- NICs: Dual 10/25G is a pleasant baseline. Keep management/BMC on a dedicated VLAN.
4) GPUs: Right‑Sizing Without Paying “Lab Tax”
You don’t need a datacenter monster to win at edge inference. Often two mid‑range GPUs beat one giant because load spreads cleanly across sessions. If you’re partition‑curious, multi‑instance features can carve one physical card into several isolated slices so you don’t tank QoS for everyone when a single job spikes.
Practical rule: If your workload is text or small‑image classification, start smaller and scale slices; for video and multi‑modal, prioritize VRAM per session. Always validate real traffic before committing to a fleet buy.
5) Power Budgeting: Honest Math Beats Hope
Add up idle, sustained, and peak draw for each component. Watch the GPU transient spikes—they’re spicier than spec sheets. Instrument with a smart PDU and clamp meter. Leave 20–30% headroom on your branch circuit and stagger GPU warm‑up at boot to avoid a brownout chorus.
| Component | Typical (W) | Peak (W) | Notes |
|---|---|---|---|
| CPU (1 socket) | 140 | 280 | Turbo and AVX bursts add up |
| GPU (per) | 400–600 | 600–700 | Design to p99 spikes |
| NVMe (per) | 5–12 | 15 | Heavy writes increase draw |
| Fans & pumps | 30–80 | 100+ | Scales with delta‑T |
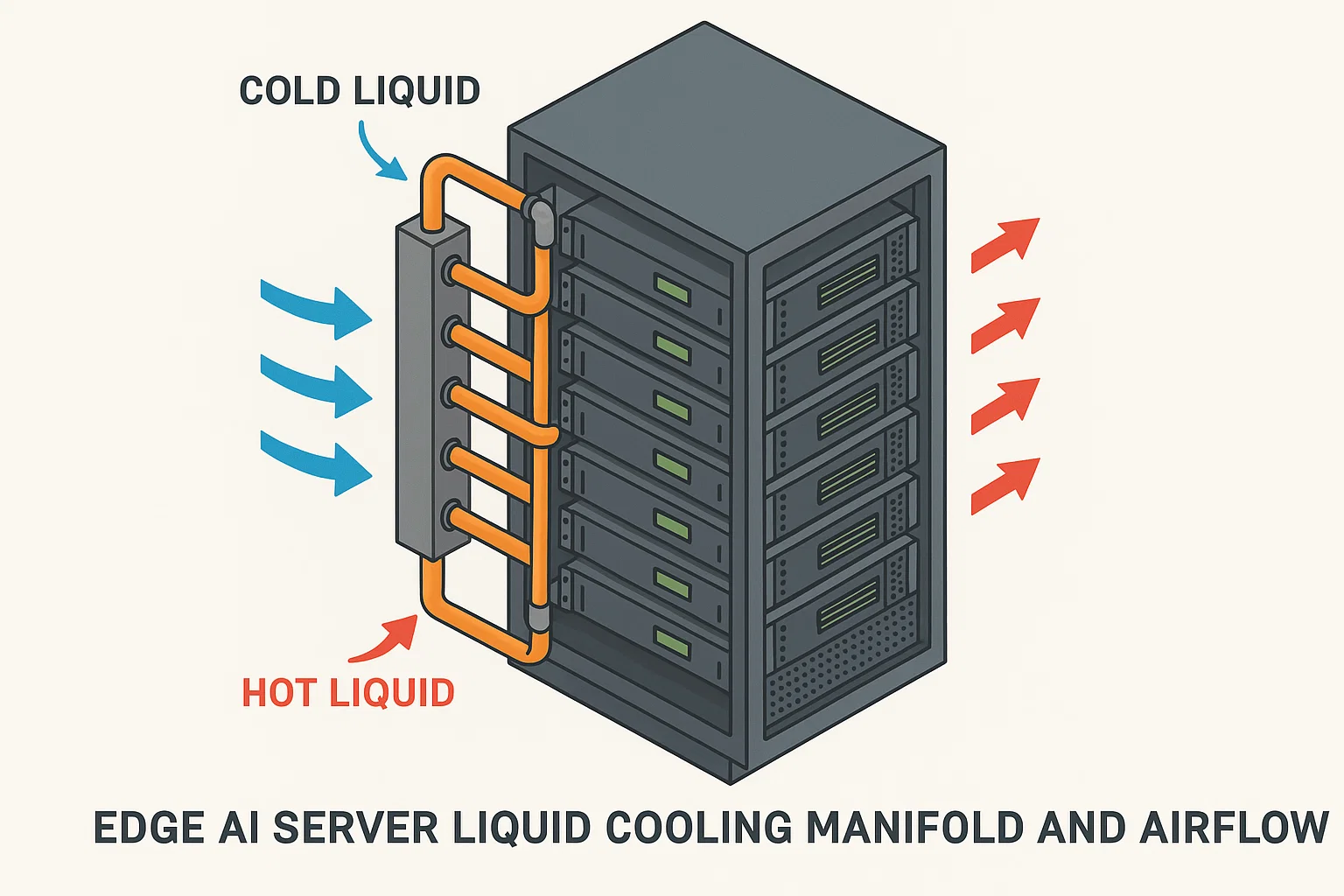
6) Cooling That Works in a Closet
Air is fine—until the room heat‑soaks. Maintain clean intake paths, add blanking panels, and keep cables from bulging into airflow. When fans start sounding like a leaf blower, test a closed‑loop liquid setup with quick‑disconnects. Instrument intake/exhaust plus hot spots near NVMe and NICs. If a big office device exhales near your rack, build a cheap baffle. No shame in low‑tech wins.
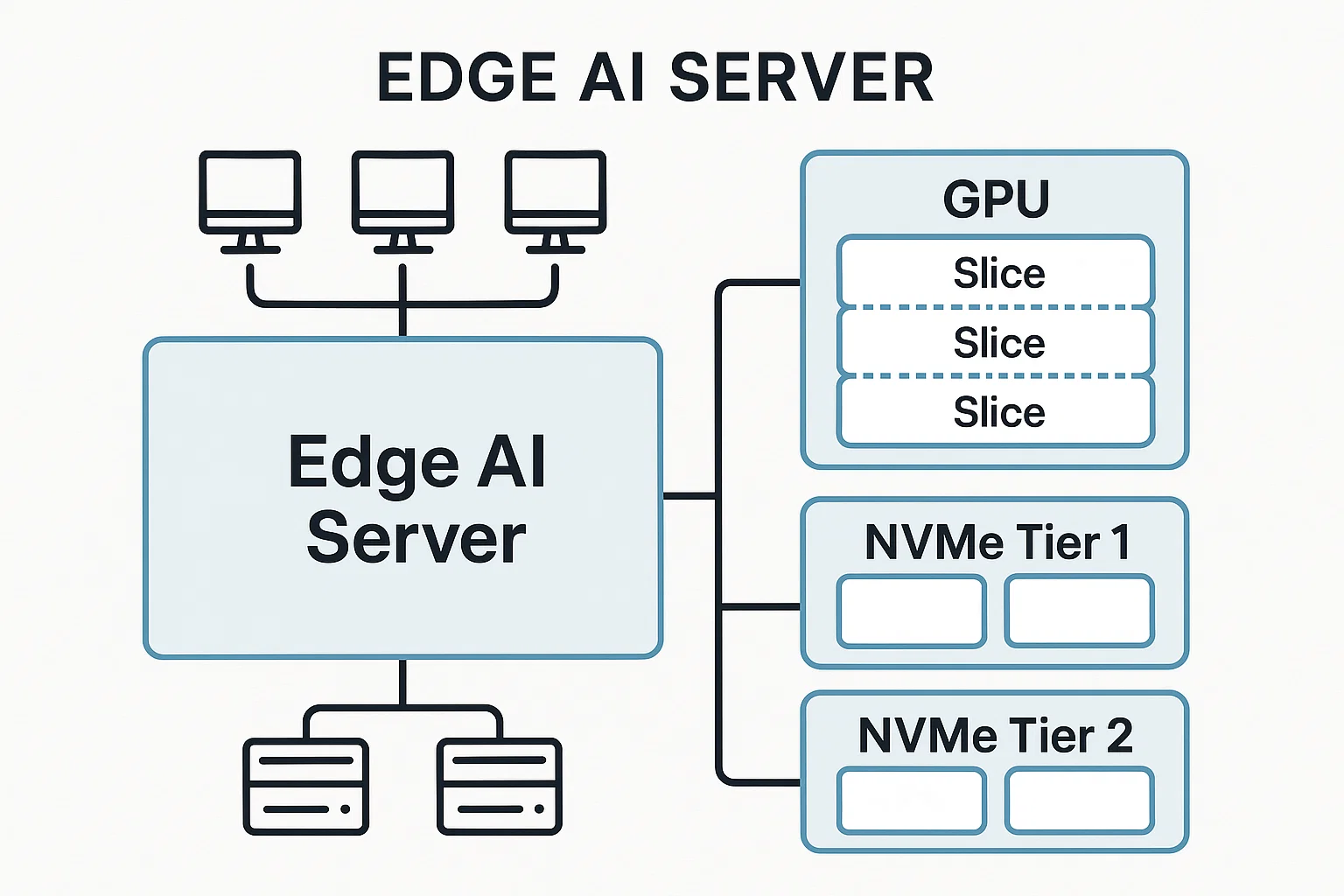
7) Storage Tiers: Make Your Data Path Predictable
Keep the critical path short. Place model weights and embeddings on Tier 1 NVMe with a fast filesystem (XFS or ZFS). Use ZFS where snapshots/checksums help, but give it RAM. Archive checkpoints to slower bulk storage. If you’re still sketching your redundancy plan, bookmark this step‑by‑step primer:
RAID Levels Explained: 12 Game‑Changing Truths for Rock‑Solid Storage
8) The Edge Network: Don’t Starve the GPUs
A hungry inference node makes a network honest. Favor mature NIC drivers, verify buffer health during peak windows, and test under ugly traffic. If you’re evaluating offload hardware, throw your worst packet stew at it—TLS termination, overlay encapsulation, storage—before you believe a glossy graph.
9) OS, Drivers, and the “Boring on Purpose” Stack
Pick a server‑grade distribution you actually know (Ubuntu LTS, Rocky/Alma). Pin kernel, GPU driver, and CUDA/cuDNN to a known‑good set. Build images you own with exact versions declared. That boring discipline saves weekends.
10) Minimal Inference Service: A Small, Honest Baseline
# Dockerfile (inference baseline)
FROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu22.04
RUN apt-get update && apt-get install -y python3-pip libssl-dev
COPY requirements.txt .
RUN pip3 install -r requirements.txt
COPY . /app
ENV TORCH_CUDA_ARCH_LIST="8.0;8.6;9.0"
CMD ["python3","/app/server.py"]11) Model Serving: Strong Defaults, Fewer Surprises
Use a serving layer that respects batching and concurrency. It should expose clear metrics (latency buckets, queue depth, GPU utilization) and play nice with health probes. It’s also worth reading an industrial primer to align terminology and options:
12) Quantization Without Regret
Start with post‑training quantization on a representative dataset. Validate with real users, not just synthetic benchmarks. Aim for “feels instant” over a tiny BLEU bump. Keep your floating‑point baseline handy so you can revert on a bad corner case. If your edge AI server handles speech or vision, evaluate per‑channel scales and mixed precision; sometimes FP8 on the bottleneck layers is the sweet spot.
13) MIG/Partitioning: One Card, Many Tenants
When multiple teams or apps share a node, partitioning features can isolate jobs. Give smallest slices to low‑priority bots and reserve fat partitions for latency‑sensitive flows. Map slices to queues so noisy neighbors don’t nuke your SLA.
14) Schedulers: Use a Queue Even on One Box
Sounds overkill? It isn’t. Even a single node with two GPUs benefits from a small scheduler that understands GPU memory, preemption, and priorities. Label nodes by VRAM class, create priority classes for p95 SLAs, and use resource quotas by team. The result is fewer accidental pileups.
15) Kubernetes Device Plugins: The One Detail Teams Forget
If you land on Kubernetes, install the GPU device plugin properly and pin versions with your driver/toolkit matrix. Liveness/readiness should reflect model health, not just container boot.
apiVersion: v1
kind: Pod
metadata:
name: summarizer
spec:
restartPolicy: OnFailure
containers:
- name: app
image: registry.local/summarizer:stable
resources:
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: weights
mountPath: /models
volumes:
- name: weights
persistentVolumeClaim:
claimName: weights-pvc16) Observability: Evidence or It Didn’t Happen
Your first dashboard should tell you three things: throughput, latency, and “is the box on fire?” Add alerts for GPU throttle, PDU near‑trip, and NVMe queue depth. Drop a quick shell loop on the host to sanity‑check everything during incidents:
watch -n 1 "\
nvidia-smi --query-gpu=utilization.gpu,temperature.gpu,power.draw --format=csv,noheader; \
iostat -x 1 2 | tail -n +7 | head -n 5; \
ipmitool sdr | egrep 'Inlet|Exhaust|CPU|Fan' "17) Security: Reduce Blast Radius by Default
- Run jobs as non‑root. No exceptions.
- Lock model artifacts as read‑only in prod.
- Rotate credentials on a schedule (not vibes).
- Separate management interfaces and BMC/IPMI onto a management VLAN.
18) Deployment Pipelines: Pin Everything
Containerize where it helps, not out of habit. Bake exact driver and runtime versions in your images. For CI, require a green “model health” check on each deploy before traffic shifts. Blue‑green is your friend when the branch office closes at 6 p.m. and you need a painless rollback.
19) Cost Truths: You Pay Either Way
Capex for chassis/GPUs/RAM/NVMe/NICs/PDUs; opex for power, cooling, people, and occasional “oops we forgot the UPS batteries.” The quiet node with margin is cheaper than the hot rod that reboots under load. The former keeps weekends free; the latter eats them.
20) Edge vs Core: Different Habits, Same Discipline
An Edge AI server may live near customers, so treat the environment like an adversary: dust, heat, curious hands. Smaller NVMe tiers, ruthless UPS planning, simpler networking. Core nodes in a data room chase outright throughput and dense cooling. Both deserve the same logging and change discipline.
21) Data Hygiene: Version Everything That Matters
- Version schema, tokenizer, prompt, pre‑/post‑processing, and weights.
- Never ship “latest” as an ID. It’s a trap.
- Snapshot daily; test restores weekly.
22) Resilience: Fail Like an Adult
- Two PDUs on separate circuits.
- Maintenance windows with clear rollback scripts.
- Weekly self‑drill: kill a service and confirm alerting and runbooks are honest.
23) Runbook Snippets I Reuse Constantly
# GPU health check
/usr/bin/nvidia-smi --query-gpu=name,driver_version,pstate,power.draw,temperature.gpu,utilization.gpu --format=csv
# Disk heat map (quick & dirty)
for d in /dev/nvme*n1; do
t=$(sudo smartctl -A "$d" | awk '/Temperature:/ {print $10}')
echo "$d $t"
done | sort -k2 -n24) Inference Patterns That Age Well
- Request coalescing: Merge micro‑requests to keep batchers busy without hurting tail latency.
- Warm pools: Keep a couple of model replicas primed for morning rushes.
- Shaping: Slow noisy neighbors; your SLA lives in p95, not mean.
25) Post‑Training Gotchas
Constrain prompts and post‑processors to structured JSON. Validate at the edge, not downstream. If your workload writes to a transactional store, throttle retries or you’ll DDoS yourself during brief network flaps.
26) Local‑First Development: Practice Where You Play
My happiest teams develop locally with the same toolchain they deploy. If you want to build a full offline workflow on your laptop first, this field guide is gold:
Claude Code local LLM — run it entirely on your machine
27) When to Scale Out (Not Just Up)
As concurrency rises, it’s tempting to grab the bigger GPU. Try scaling replicas first. If the customer experience hinges on p95 under 150 ms, ask whether your next dollar reduces variance more by adding a second mid‑tier card or one flagship. The answer is often “two decent cards.” That keeps your edge AI server flexible when a new team wants a small tenant.
28) Minimal Firewall & Hardening
# Example: UFW baseline
ufw default deny incoming
ufw default allow outgoing
ufw allow ssh
ufw allow 8000/tcp # inference
ufw allow 9100/tcp # node exporter
ufw enable29) UPS, Brownouts, and Honest Maintenance
Plan for a 10–15 minute graceful shutdown, not infinite runtime. Test quarterly. Label the rack with support contacts, IPs, and a “don’t block this vent” sticker. It sounds goofy until a delivery palette suffocates your intake.
30) Benchmarks That Matter (and the Ones That Don’t)
Use your traffic. Synthetic leaderboards are fun, but your actual tokenizer latency, payload sizes, and response shaping will make or break the feel. Chase smoothness. A model that replies in 120 ms beats a genius that needs a nap.
31) Documentation Breadcrumbs Your Team Will Actually Read
- One README per service with start/stop, health probe, and metrics URLs.
- “Break glass” rollback instructions next to every deployment job.
- Runbook links from alerts—don’t make folks spelunk in a wiki at 2 a.m.
32) Copy‑Paste Boilerplates You’ll Use Weekly
# systemd service
[Unit]
Description=Edge Inference
After=network.target
[Service]
User=infer
WorkingDirectory=/srv/infer
ExecStart=/usr/bin/python3 /srv/infer/server.py
Restart=on-failure
Environment=PYTHONUNBUFFERED=1
[Install]
WantedBy=multi-user.target33) A Few Outside Reads Worth Your Coffee
When you need deeper dives on serving stacks, quantization, and edge‑friendly networking patterns, these pieces consistently pay off:
Practical Build Checklist (Print This)
- Sketch power math to p99. Order the PDU you actually need.
- Lay out PCIe/GPU topology; avoid cross‑socket unless intentional.
- Define storage tiers and format the fast tier for weights/embeddings.
- Pin kernel/driver/toolkit; build a known‑good base image.
- Install serving with batching and health probes. Export metrics day one.
- Set up dashboards + alerts for throttle, queue depth, and PDU near‑trip.
- Write the rollback script before the first deploy.
- Label the rack and test the UPS. Don’t skip this.
Related Deep Dives on FoxDooTech
These long‑form guides expand on topics we touched above:
- AI Server: 31 Brutally Practical Lessons for GPU‑Ready Racks — a comprehensive operating manual for GPU nodes.
- RAID Levels Explained — make smart redundancy choices without the jargon hangover.
- Claude Code local LLM — ship features when the network goes grumpy.
Final Thoughts
If you remember nothing else, remember this: design for the worst five minutes, not the best five hours. Put your edge AI server on a forgiving power budget, give it clean air, keep the data path short, and make the scheduler your buddy. Do those four things and the rest is just reps—calm deployments, tidy dashboards, and a box that quietly does its job while the team goes home on time.
And hey, if you’re staring at a broom‑closet rack right now, wondering whether to move the printer or the server—move the printer. Your GPUs will thank you.





