I first felt Agentic AI getting real on a Tuesday night when a flaky API started thrashing our checkout pipeline. Before I even reached for my phone, an agent spun up a canary, rewrote a failing health probe, and dropped an annotated Slack thread with graphs and a rollback plan. I still had to approve the change, but the “plan + diff + blast‑radius” showed up faster than my espresso machine can warm up. That was the moment I stopped seeing agents as flashy demos and started treating them like junior teammates that don’t get tired or ego‑hurt.
So this isn’t theoretical. It’s the practical guide I wish I had six months ago—what to build, what to avoid, and how to ship something that cuts tickets and cost instead of adding new dashboards nobody reads. If you’re ready to turn Agentic AI from buzz to business outcomes, let’s get into it.

What “Agentic AI” Actually Means for IT (Not a Hype Definition)
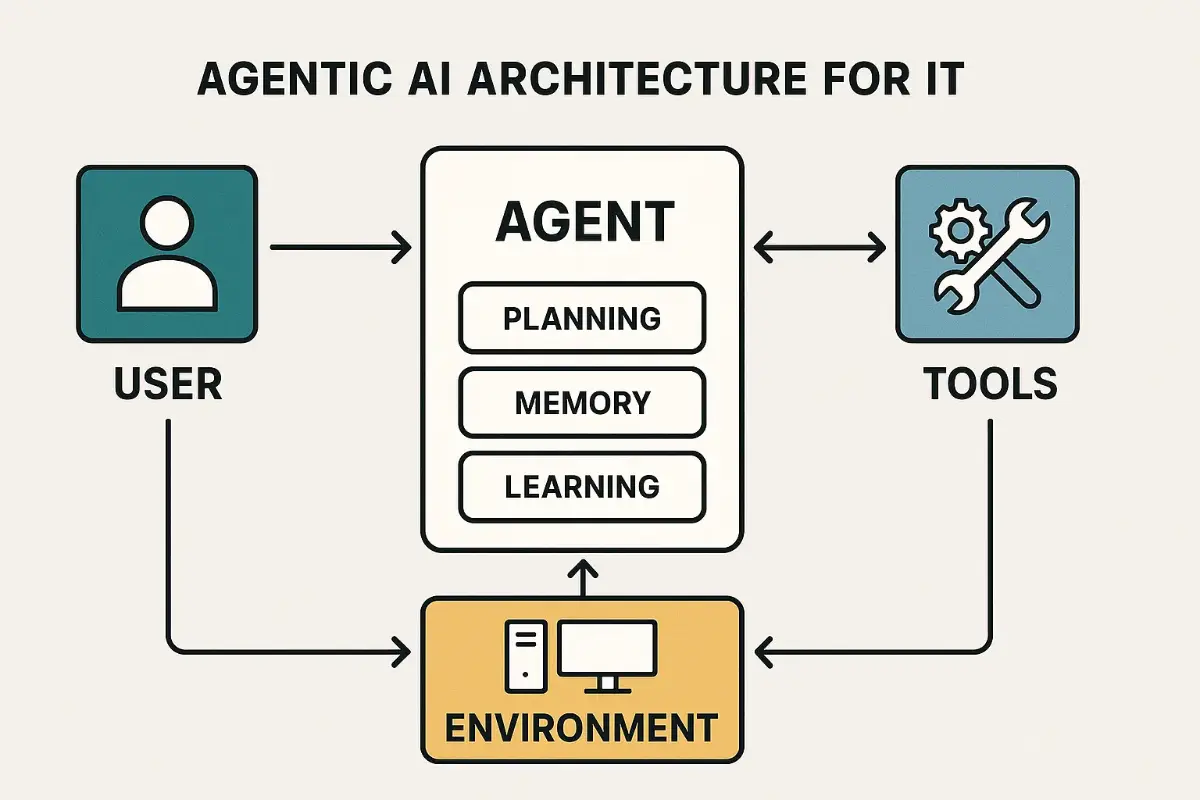
Plain English: an agent is software that understands a goal, chooses tools, and executes a multi‑step plan while reporting back. In IT, that means an agent can read alerts, consult runbooks, call APIs (cloud, firewall, CI/CD), simulate a change, and propose (or execute) the fix with guardrails. The magic isn’t just language models—it’s the loop: goal → plan → act → observe → adjust.
- Planner: breaks a vague intention into ordered steps.
- Tooling layer: safe adapters for ticketing, infra, security, and data.
- Memory: short‑term scratchpad plus durable knowledge (docs, configs, runbooks).
- Feedback: telemetry and logs to verify impact and roll back fast.
- Policy: permissions, approvals, and audit trails so you can sleep at night.
In short: only the combo of planning + tools + feedback makes Agentic AI production‑worthy for IT. Models alone are clever; agents get work done.
Why Now? The Three Forces Behind the Shift
Three currents are turning the tide:
- APIs everywhere: Cloud, CI/CD, and ITSM are programmable, so agents can actually do things.
- Observability maturity: Metrics/traces/logs unify intent with proof. Agents don’t guess; they measure.
- Human-in-the-loop patterns: Approvals, simulations, and sandboxes offset risk without killing speed.
These are the levers that make Agentic AI feel less like magic and more like a very fast teammate.
Reference Architecture You Can Reuse Tomorrow
You can ship this in a week if you already have basic observability and an ITSM. Here’s the minimal architecture that scales:
1) Event Bus
Normalize signals: alerts from Prometheus, tickets from Jira/ServiceNow, webhooks from cloud providers. Add a tiny schema (entity, severity, environment, source) so your planner isn’t parsing 27 alert formats.
2) Planner
The planner turns “cart API error rate spiking” into a plan: check dashboards, fetch recent deploys, run health checks, estimate blast radius, propose fix, run in staging, and ask for approval.
3) Tools Layer
Wrap your power tools with strict interfaces—no raw shell on prod. Think run_k8s_cmd(namespace, action, manifest), toggle_waf_rule(id, on_off), open_change_request(summary, diff).
4) Policy & Guardrails
Define who can approve what. A staging restart might be auto‑approved; a prod database failover always needs a human. Everything writes to an immutable audit log.
5) Observability Feedback
Every action attaches success metrics it expects to improve—latency, error rate, queue depth—and monitors them for X minutes post‑change. If not fixed, roll back and page a human.
Build Your First Ops Agent (Starter Kit)
Here’s a cut‑down starter agent that’s worked for us: scope one service, wire three tools, require approval for prod. Keep it boring and prove value within a sprint.
Core Python Skeleton
class OpsAgent: def __init__(self, itsm, kube, o11y, approvals, policy): self.itsm = itsm # create/update tickets self.kube = kube # safe K8s actions self.o11y = o11y # query metrics/logs self.approvals = approvals self.policy = policy
ruby
Copy
def plan(self, goal):
return [
{"step": "fetch_metrics", "service": goal["service"]},
{"step": "check_recent_deploys", "service": goal["service"]},
{"step": "run_healthcheck", "service": goal["service"]},
{"step": "propose_fix", "strategy": "roll_pods"},
{"step": "simulate", "env": "staging"},
{"step": "request_approval", "change": "prod_roll"},
{"step": "execute", "env": "prod"},
{"step": "verify", "duration_min": 5},
]
def act(self, plan):
for step in plan:
# ...call tool adapters, write audit trail, handle exceptions...
pass
Minimal Runbook as Data
service: cart-api slo: latency_p95_ms: 300 error_rate: 0.5 actions: simulate: cmd: kubectl -n staging rollout restart deploy/cart-api execute: cmd: kubectl -n prod rollout restart deploy/cart-api verify: queries: latency: rate(http_request_duration_seconds_bucket[5m]) errors: sum(rate(http_requests_total{status=~"5.."}[5m])) policy: prod_requires_approval: true approvers: ["oncall-primary","sre-lead"] Safety Wrapper for Tools
def run_kubectl(namespace, verb, resource): assert namespace in {"staging","prod"} assert verb in {"rollout","scale"} # execute with a locked-down service account + audit annotation ... Where Agents Shine: Five Real‑World Plays
1) Incident Triage in Minutes, Not Mayhem
An alert fires: p95 latency explodes. The agent auto‑correlates a fresh deploy, runs a synthetic check, scrapes logs for error signatures, and proposes a canary rollback. It drops a Slack thread containing graphs, diffs, and a one‑click approval button. You confirm; it rolls back, watches metrics for five minutes, and posts the green check. That’s Agentic AI as a teammate.
2) Wi‑Fi Meltdowns Without “Walk the Floor” Guesswork
When devices cling to the wrong band, support queues explode. If this problem hits your estate, this practical guide—Dual‑Band WiFi – 9 Fatal Traps Most Enterprises Get Wrong—pairs nicely with an agent that can scan RF stats, apply minimum data rates, and stage SSID tweaks with approvals attached. Agents orchestrate the change; your team keeps control.
3) Cost Controls that Don’t Kill Performance
Agents watch capacity headroom and right‑size resources on schedule. If you’re designing day‑2 ops, I strongly recommend this deep dive: Enterprise Network Deployment Playbook – Part 5: Post‑Deployment Monitoring, Scaling & Optimization. Pair its observability tactics with an agent that forecasts trends and submits change requests automatically.
4) Security Fixes You’ll Actually Ship
Pipeline an agent to open patch tickets, test mitigations in staging, and propose a phased rollout. Keep high‑risk moves human‑gated. A well‑configured Agentic AI will nag the right owner, attach repro steps, and carry the change to done instead of letting issues rot.
5) Golden Paths for New Services
Wrap your “new microservice” template as a single agent command: scaffold repo, set policies, wire dashboards, register SLOs, and spin a sandbox. Repeatable, auditable, boring—in the best way.
Governance: Trust Is a Feature, Not an Afterthought
I’ve said “no” to clever demos that ignored compliance. Production‑grade Agentic AI needs:
- Least privilege: each tool adapter runs with minimal scope and rotates credentials.
- Approvals by risk: no agent should have unconditional prod rights.
- Immutable audit: every prompt, plan, action, and metric result lands in write‑once logs.
- Policy as code: treat permissions like Terraform—reviewed and tested.
Data Layer: Docs, Runbooks, and the RAG Reality Check
Your agent’s “knowledge” starts with your own material: service docs, runbooks, postmortems. Embeddings search helps but isn’t the whole story. Mix retrieval with structured sources (CMDB, SLO catalogs, ticket history) for precision. Keep a hand‑curated FAQ for the top 50 playbooks your on‑call team reaches for. That’s what makes Agentic AI answer with “do this next” instead of “here’s a paragraph.”
Observability: Close the Loop or Don’t Bother
Every action must predict an outcome and verify it. If an agent rolls pods, it should watch p95 latency and error rate for five minutes and roll back if the slope looks bad. Tie this into your alerts so the same thresholds that paged you also sign off the fix. Only then does Agentic AI translate to fewer 3 a.m. wake‑ups.
Security: Guardrails that Move as Fast as Your Agents
Agents make it easier to ship good security habits: enforced passkeys, auto‑rotated secrets, automated hardening checks, and nudge‑bots that chase owners for overdue patches. The trick is keeping approvals meaningful. A production DB action might require two approvers, artifact checksums, and a staged read‑only test before write access is granted.
FinOps: Forecast Before You Overspend
Cost reductions are boring—until they pay for capacity you’ll need next quarter. Wire agents to your billing APIs and deploy a simple forecasting model (even a rolling average or Holt‑Winters can get you 80% there). When forecasts breach thresholds, the agent files a ticket with context and a suggested plan instead of just pinging Slack with a scary graph. That’s where Agentic AI earns budget love.
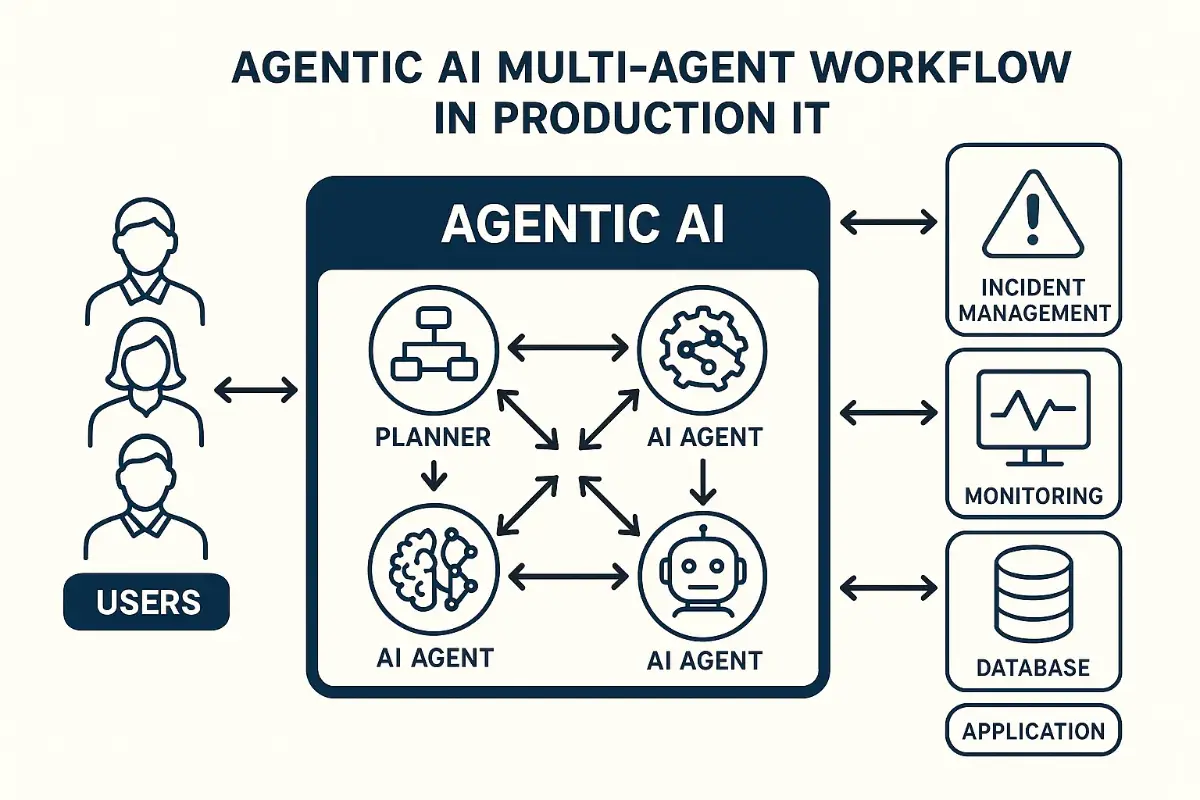
Multi‑Agent Patterns That Actually Work
- Manager‑worker: a coordinator plans; small workers run tasks with narrow permissions.
- Router: a lightweight gatekeeper sends requests to specialized agents (network, database, app).
- Critic: a separate agent checks plans for policy and compliance before execution.
Keep agents small, opinionated, and observable. A tangle of “do‑anything” bots is how you rebuild the spaghetti you were trying to escape. Focus each Agentic AI on one job and one set of tools.
30‑60‑90 Day Rollout Plan (Battle‑Tested)
Days 1‑30: Prove Value
- Pick one service, one SLO, one action. Ship a staging‑only agent.
- Instrument everything; measure tickets avoided and time saved.
- Write down what the agent can’t do yet. That doc saves arguments later.
Days 31‑60: Expand Carefully
- Add two more tools (CI/CD, firewall) with locked‑down scopes.
- Introduce approvals tiers and rotate credentials automatically.
- Attach a monthly value report to your exec update (incidents avoided, MTTR delta, cost trims).
Days 61‑90: Harden & Scale
- Split into specialized agents (network, app, database).
- Refactor runbooks as data; reduce prompt spaghetti.
- Chaos‑test: deliberately break a staging service and watch the agent recover it under supervision.
KPIs: Score What Matters
| KPI | Definition | Target |
|---|---|---|
| MTTR (agent‑assisted) | Mean Time To Resolve when an agent proposes the fix | < 30 minutes |
| Approval latency | Time between agent proposal and human decision | < 5 minutes |
| Rollback rate | Percentage of agent actions that auto‑rollback | < 5% |
| Ticket deflection | Incidents closed without human hands | ≥ 20% after 60 days |
| Policy violations | Denied attempts due to permissions | Zero in prod |
The Human Side: Keep Engineers in the Loop
People accept fast teammates; they resist black boxes. Make agents transparent: show the plan, show the tools, show the expected metrics, and make the “why” readable. When Agentic AI explains itself, your team leans in instead of creating shadow workflows.

Anti‑Patterns That Will Bite You
- Agent sprawl: one giant bot that “does everything” will do nothing well. Split responsibilities.
- Silent failures: if action logs aren’t piped to chat and SIEM, you’ll miss partial outages.
- Raw shell access: wrap tools. Never let an agent improvise a prod bash command.
- RAG or bust: retrieval helps, but runbooks as data and structured APIs are what make fixes real.
Hands‑On Examples You Can Copy
Slack Approval Payload
{ "title": "Prod rollout restart proposal", "service": "cart-api", "reason": "p95 latency above 300ms after deploy", "actions": [ {"simulate": "kubectl -n staging rollout restart deploy/cart-api"}, {"execute": "kubectl -n prod rollout restart deploy/cart-api"} ], "blast_radius": "cart-api only; 3 replicas; HPA min=3", "expected_metrics": ["p95 < 300ms", "errors < 0.5%"], "approve_url": "https://itsm.local/changes/123/approve", "rollback_url": "https://itsm.local/changes/123/rollback" } Firewall Toggle as a Safe Adapter
def toggle_waf_rule(rule_id: str, on: bool) -> dict: assert rule_id.startswith("waf_") payload = {"id": rule_id, "enable": on} # signed request via mTLS; limited to specific zones resp = requests.post("https://edge.waf.local/api/rule", json=payload, timeout=5) return {"status": resp.status_code, "ok": resp.ok} Edge vs. Cloud: Where Should Agents Live?
Latency matters. A build agent in the same region as your cluster can loop faster, while a security agent tied to your SIEM is fine sitting in the cloud. For remote sites with shaky WAN, consider local agents on tiny NUCs—or even laptops with NPUs—to run checks without waiting on the internet. That’s another spot where Agentic AI punches above its weight: right next to the problem.
Interlude: A Quick Shop‑Floor Story
We rolled into a manufacturing plant after a nasty week of packet loss and angry walkie‑talkies. The agent started by mapping trouble spots, nudged a few AP power levels, and suggested a separate SSID for handheld scanners. Humans okayed it; throughput jumped. Nobody asked about “AI”—they just wanted the error lights to stop blinking. That’s what sold me on the approach.
Tooling Landscape (Use Whatever Fits… But Keep It Small)
You can build with open‑source stacks, vendor platforms, or a mix. The litmus test is simple: can you log every step, cap permissions, and roll back safely? If the answer’s no, it doesn’t belong in your production loop. Keep your Agentic AI thin, modular, and observable.
Further Reading (High‑Authority, Optional)
When you want a broader market view, these resources are solid:
- Gartner’s 2025 technology trends
- McKinsey’s technology trends outlook
- Cloudflare engineering & network posts
Your Next Move
Pick one service. Wire three tools. Ship a staging‑only loop that plans, acts, and verifies with human approval in the middle. That’s it. If it saves your on‑call an hour a week, expand it. In a month, you’ll have Agentic AI that pays for itself. In a quarter, it’ll be the quiet hero behind your best uptime numbers.
Key Takeaways (Pin These)
- Show the plan: transparency beats “trust me.”
- Attach metrics to actions: no green checks without proof.
- Guardrails win hearts: approvals, least privilege, immutable logs.
- Stay small: specialized agents beat kitchen‑sink bots.
- Iterate weekly: one new tool or playbook per sprint keeps momentum.
Bottom line: the best way to make Agentic AI real is to treat it like a teammate—clear goals, tight permissions, and constant feedback. Do that, and the 3 a.m. pager becomes a lot less scary.





