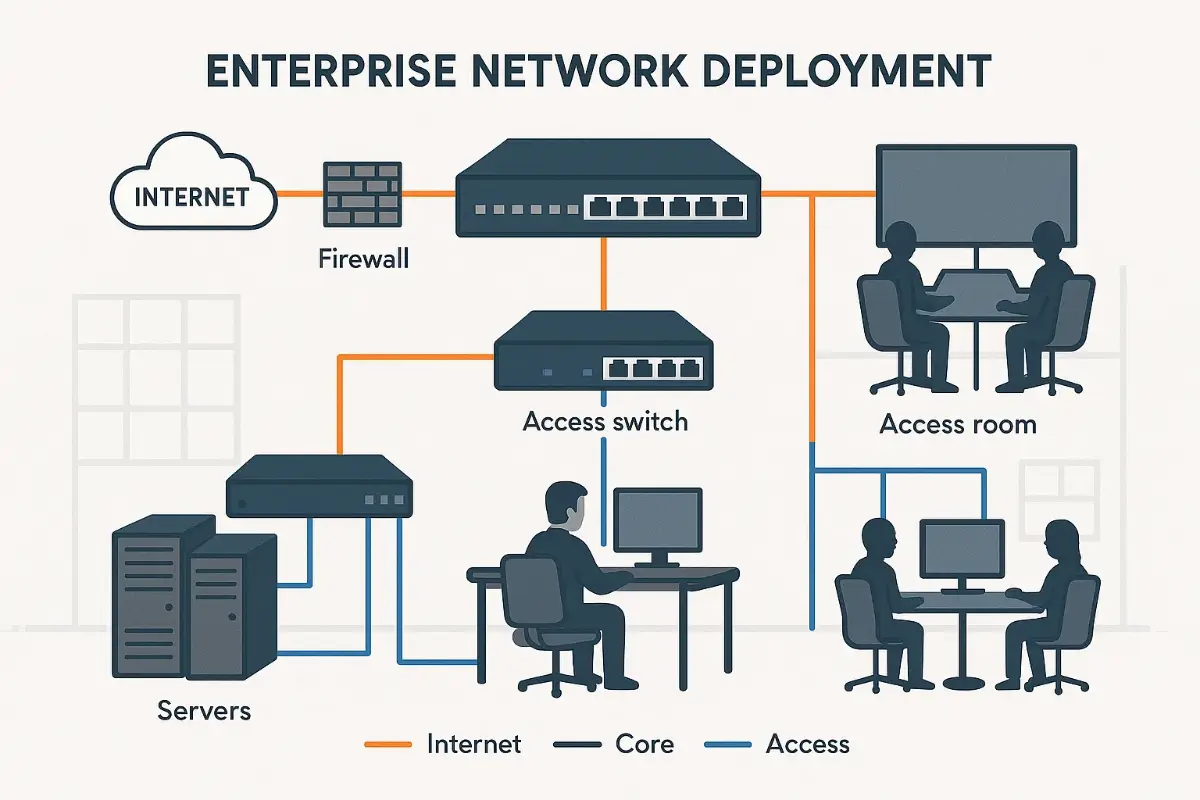
Enterprise Network Deployment gets brutal once gear leaves the warehouse. In this part of the playbook we act as the external managed-service provider who owns every SLA and every panic call—not the client’s internal IT crew. Our mission: transform the signed architecture from Part 2 into blinking LEDs, routed packets, and a cutover that feels boring (because boring means nothing broke).
Project Mobilization & Supply-Chain Logistics
The clock starts the second the purchase order lands. We immediately spin up a Mobilization War-Room in Jira with three swim-lanes:
- Procurement + Shipping – track lead times, pallet weights, customs docs.
- Staging + QA – prep configs, burn-in tests, compliance labels.
- Field + Cutover – site access windows, lift-gate trucks, hot spares.
Each switch or firewall SKU inherits a template task that lists serial-number capture, software version pinning, and QA result upload. Miss a step now and your Enterprise Network Deployment could die at customs or—worse—boot with a vulnerable firmware.
Build the Staging Environment: “One Rack to Rule Them All”
We rent a small colocation cage near our NOC, power it with dual 30 A circuits, and build a replica of the production leaf-spine core—just two leafs and one spine, but running identical OS versions. Automation pipeline connects to this cage first:
# nornir-config.yaml (excerpt)
inventory:
plugin: SimpleInventory
options:
host_file: inventory/hosts.yml
group_file: inventory/groups.yml
runner:
plugin: threaded
options:
num_workers: 10
defaults:
connection_options:
netmiko:
extras:
session_log: logs/nornir_session.log
Every nightly build lints configs, pushes to the staging rack, then runs pyats health --testbed staging.yaml. Only green passes unlock the “Ready to Ship” status. That discipline slashes field rework and anchors Enterprise Network Deployment quality.
Physical Layer Execution: Cabling, Labeling, and Power Maps
Enterprise clients rarely budget time for rewiring, yet messy cables wreck airflow and audits. Our field techs follow the Four-Color Rule—blue for data, green for management, yellow for high-availability interlinks, red for out-of-band console. Labels include rack-unit, port, and destination. We document with NetBox QR codes: one scan shows the port’s logical diagram, MAC, and patch-panel destiny.

Device Configuration & Automation Pipeline
Enterprise Network Deployment lives or dies on reproducible configs. The pipeline:
- Git commit triggers GitLab CI.
- CI spins up containerized EVE-NG lab, loads the config, runs ping mesh, BGP neighbor health, and RESTCONF probes.
- On success, a signed artifact (SHA-256) gets pushed to an S3 bucket.
- Field tech grabs the artifact URL and flashes gear via
ansible-playbook flash.yml; SHA mismatch aborts.
This air-gap-friendly flow means no engineer edits configs onsite—reducing fat-finger risk and logging every change for post-mortems.
Pilot Branch & Parallel Run Strategy
Even perfect labs hide real-world quirks: ISPs with jumbo-frame allergies, badge readers running Telnet. We therefore stand up a Pilot Branch first—often the HQ lab or a smaller office. Traffic mirrors between legacy and new fabrics using SPAN and an optical TAP. We flip 10 % of users for a week, compare KPIs, then adjust QoS or ACLs before full cutover.
Staging script snippet:
# mirror critical VLAN 20 to legacy core
interface TenGig1/0/48
description PilotBranch_Mirror
switchport mode trunk
switchport trunk allowed vlan 20
monitor session 1 source interface TenGig1/0/48
monitor session 1 destination interface TenGig1/0/52
Cutover Plan: Big-Bang vs. Phased Rollout
Two schools of thought:
| Approach | Pros | Cons |
|---|---|---|
| Big-Bang | Single change window, simple rollback | High blast radius, longer outage risk |
| Phased | Smaller fault domains, learn per site | Extended dual-fabric support, more logistics |
We typically hybridize: core data-center big-bang at midnight Saturday, then phased SD-WAN branch activations over two weeks. Each site shift triggers automated smoke tests—curl https://healthcheck.enterprise.com—and a ServiceNow ticket moves from “Scheduled” to “Operational.”
Go-Live Readiness Checklist
Seventeen checkpoints stand between staging and green-light:
- All gear on final OS versions (N-1 long-term release).
- Golden config hash matches signed artifact.
- Diversified power feeds on UPS with 30 % spare headroom.
- Out-of-band LTE modem online and tested.
- Syslog, NetFlow, and SNMP traps flowing to SIEM.
- Change-freeze exception signed by CIO.
- Stakeholder comms drafted—who to call, when.
- Rollback script saved locally & on secure USB.
- Escalation matrix with cell numbers printed and laminated.
- Maintenance window calendar invite accepted by all.
- Parallel run success metrics (latency, error rate) inside Grafana.
- Backup of legacy configs and DB snapshots.
- Firewall baselines committed, NAT translations validated.
- DR site routing table reflecting new prefixes.
- RADIUS / LDAP AAA synced with new NAS-IDs.
- Certificate validity > 6 months for TLS termination.
- Legal approves updated SLA clock start.

Rollback & Contingency Tactics
Enterprise Network Deployment reality: something breaks. Our rollback rule—15 minutes to fix or flip back. Legacy gear stays cabled and powered but admin-down. The rollback script:
# cutover failure? restore legacy core uplink
interface Port-Channel1
shutdown
!
interface Port-Channel2
no shutdown # legacy link
DNS TTLs remain at five seconds during the window. If we revert, clients recover before coffee cools.
Hypercare & Knowledge Transfer
First 72 hours post-go-live we run a war-room Slack channel with automated reports every 15 minutes—latency histogram, CPU, BGP flap count. Any red flag creates a PagerDuty “P1” that wakes our follow-the-sun NOC. After a week, cadence drops to hourly, and we deliver:
- Run-Book Videos – screen-captures of common tasks.
- As-Built Drawings – exported from NetBox to PDF.
- Root-Cause Archive – all incidents + fixes.
We also cross-train the client’s NOC with our Windows 11 Black Screen crash guide and advanced security checks from the Microsoft Defender deep-dive—because resilient endpoints lighten the network load.
Quick Anecdote: Midnight Bank Cutover Gone Right
Last winter a regional bank hired us to shift their core from aging Cat6K to a VXLAN leaf-spine fabric. We had a 4-hour window. At 01:07 the new spine misread a CRC and dropped OSPF adjacencies. Our pipeline blocked the commit, fired the rollback, and legacy traffic resumed in ninety seconds. We swapped the faulty optic, re-ran CI tests, and still finished by 04:00. CFO called it a “non-event”—the highest compliment an outsourcer can get.
External Resources for Further Mastery
- Ansible Network Automation Guide – solid playbook patterns for multi-vendor gear.
- Packet Pushers Blog & Podcasts – real-world war stories and design critiques.
What’s Next?
With implementation steady and go-live tactics proven, Part 4 dives into Security-First Operations—zero-trust fine-tuning, continuous compliance scans, and breach-ready playbooks. Stay tuned, and bookmark this Enterprise Network Deployment series for every future rollout.