Qwen3-0.6B isn’t a lab toy anymore—it’s the kind of small language model that quietly makes big systems better. I learned that the hard way one Friday night: a checkout pipeline lagged, ad bids were missing windows, and we didn’t have the budget to shove a 70B beast into the hot path. We dropped a tiny Qwen3-0.6B stage in front, cleaned queries, screened junk, trimmed context—and the graphs calmed down before the pizza got cold.
That’s the spirit of this deep dive: how Qwen3-0.6B wins the last mile where milliseconds matter, why it’s perfect for safety triage, how it flies on-device, and where it shines as a pretraining backbone. I’ll show patterns you can copy tomorrow—plus the trade-offs you shouldn’t ignore.
Qwen3-0.6B and the “last mile” your big model can’t (or shouldn’t) run
In modern stacks, the heavy model doesn’t have to do every job. The last mile is crowded with small, sharp tasks: query rewrite, intent detection, semantic tweaks, light scoring. Qwen3-0.6B excels here because it’s fast, cheap, and good enough to move the needle without torching your GPU budget.
Every millisecond costs money
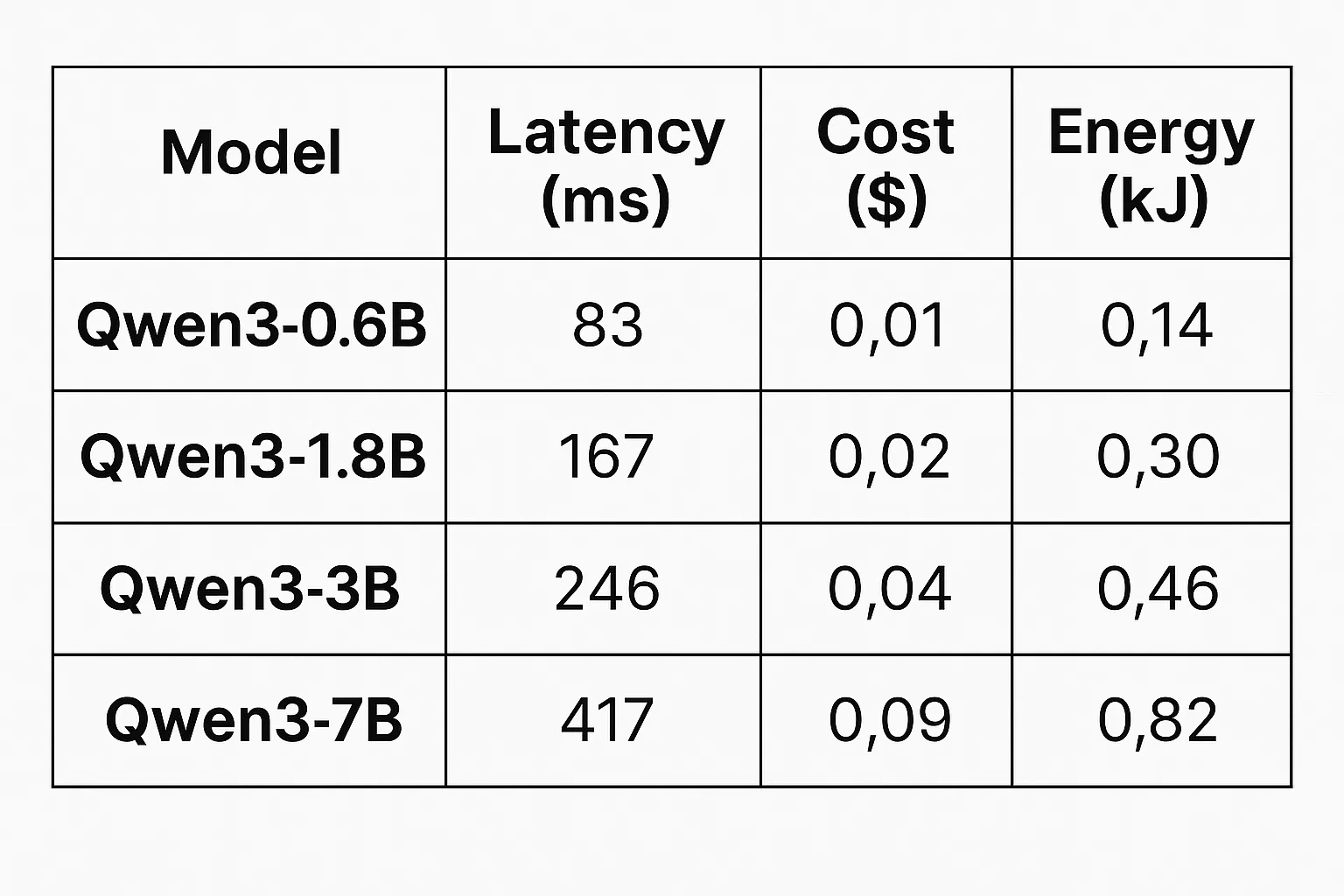
High-QPS systems—search, recommenders, ad auctions—count time in milliseconds. A 7B or 70B model can be brilliant, but it’s also a tax on latency and cost. A small gate powered by Qwen3-0.6B lets you improve hit quality by 5–10% with a fraction of the compute. On many paths, that’s the difference between hitting your p95 and paging the on-call.
- Query rewrite: normalize, disambiguate, and canonicalize user intent before recall.
- Semantic augmentation: add missing synonyms and facets (“budget phone” → “affordable smartphone”).
- Lightweight scoring: quick, explainable nudges before the heavy ranker.
- Embedding recall: rewrite for better vector hits while keeping BM25 honest.
// Example: tiny rewrite + safety gate before search function preprocess(userQuery) { const cleaned = slm_rewrite(userQuery); // Qwen3-0.6B if (!slm_moderate(cleaned)) return {blocked: true}; // Qwen3-0.6B return {q: cleaned}; } When the upstream is “query × thousands of items,” the math snowballs. Running a 0.6B model once to prep the query is often the only viable way to keep the downstream sane. That’s Qwen3-0.6B acting like WD-40 for your ranking pipeline—quiet, cheap, effective.
The “query × item” multiplication trap
Multiply one query by thousands of candidates and you’ve got a micro-DDoS against your own compute. Every billion parameters you add to the scoring model grows cost and latency non-linearly. The elegant escape is to handle the first 80% with a small, fast pass. In practice, Qwen3-0.6B is a perfect front door: pre-filter nonsense, map intent, enrich with a few synonyms, and pass a tighter candidate set to your heavy ranker.
| Stage | Model | Typical Work | Latency Budget | Cost |
|---|---|---|---|---|
| Preprocess | Qwen3-0.6B | Rewrite intent + safety | 1–5 ms (CPU/NPU) | Minimal |
| Recall | Embeddings + BM25 | Fast candidate set | 10–30 ms | Low/Medium |
| Re-rank | 7B–13B (optional) | Top-N refinement | 25–90 ms (GPU) | Medium/High |
Notice what’s happening: by the time the big model wakes up, Qwen3-0.6B already did the boring, high-leverage work—and your SLOs are safer.
The first safety gate: block the obvious 99% and escalate the rest
Content safety is the toll booth every production LLM must pass. If you try to run every prompt through a giant model just to say “no,” the meter explodes. A better design is a two-stage “fast screen → slow review.” Small models shine here, and Qwen3-0.6B is ideal as a high-recall pat-down that slams the door on clear violations and defers the edge cases.
- Small gate (Qwen3-0.6B): cheap, strict, and fast. Blocks the obvious stuff in one hop.
- Heavy reviewer: only for the ~20% that needs nuanced judgment, logging, and reasoned feedback.
// Pseudo-service: fast moderation powered by Qwen3-0.6B POST /moderate { "text": "...", "userId": "123" } Response: { "allow": false, "reason": "hate_speech", "gate": "qwen3-0.6b" } This is reliability engineering, not just AI. The small gate keeps p50 low and variance tight; the big reviewer handles the weird stuff. And since Qwen3-0.6B can run on CPU or mobile NPU, you can move parts of the gate to the edge for extra privacy and resilience.
On-device king: speed, privacy, and “it just works” UX
The best AI features are invisible. Notes that summarize themselves. Emails that auto-draft a tidy response. A voice command that flips into a calendar reminder. When these micro-interactions happen on the device, the experience is instant and private. That’s where Qwen3-0.6B feels made-to-measure.
Why on-device matters
- Latency you can feel: no round trips, no flaky Wi-Fi, no battery-melting retries.
- Privacy by default: sensitive text never leaves the device when Qwen3-0.6B runs locally.
- Cost that trends to zero: no per-token cloud bill for the common stuff.
- Graceful degradation: features keep working offline; sync later.
In tests and real use, a well-quantized Qwen3-0.6B can stream tokens fast enough to feel native. Couple it with tool-calling (MCP-style) for local calendars, reminders, and files, and suddenly “assistant features” are just another part of the OS.

Developer ergonomics: it plugs into your stack
For local workflows, you can wire Qwen3-0.6B behind an OpenAI-compatible endpoint, making editors and tools happy. If you’re curious how we run local models alongside our IDEs, this hands-on guide shows the exact steps we use in the field: Claude Code local LLM — the field-tested way to run it entirely on your machine.
The overlooked base value: a “pretraining backbone” you can actually iterate
Too many teams think “chatbot” and stop there. Small models can also be the new BERT: a sturdy base to fine-tune, distill, or continue pretraining on your domain. The magic is iteration speed. You don’t need a cluster to try an idea before lunch. Qwen3-0.6B invites more experiments, which typically leads to better task fit.
- Continue pretraining: extend the model’s world with high-quality domain text.
- Supervised fine-tunes: a few k curated examples go a long way on Qwen3-0.6B.
- Distillation to durable skills: compress a larger teacher into a faster student.
- LoRA/QLoRA on a single GPU: cost-controlled upgrades without a data-center bill.
# Sketch: LoRA for a small classification/formatting head from peft import LoraConfig, get_peft_model from transformers import AutoModelForCausalLM, AutoTokenizer base = "qwen3-0.6b" # placeholder id, wire to your local registry tok = AutoTokenizer.from_pretrained(base) m = AutoModelForCausalLM.from_pretrained(base, load_in_4bit=True) cfg = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj","v_proj"]) m = get_peft_model(m, cfg) # Train on your redlines/formatting dataset → export adapter → serve near CPU edge. If you’re building larger automations around these tuned skills, we’ve also shared a practical playbook for multi-step, production-ready chains and agents: n8n AI Workflow: 21 Brilliant Power Moves for Fail-Safe Automation.
Recipe: where Qwen3-0.6B fits inside a production pipeline
- Ingress: text arrives from UI/API. Normalize encoding, strip markup.
- Gate 1, small & strict: run Qwen3-0.6B for safety + intent. Block obvious violations; map goal.
- Query rewrite: reshape the text for recall; keep a reason code for observability.
- Recall: hybrid vector + lexical. Attach citations/IDs only, not the whole docs.
- Optional re-rank: if the business case justifies it, use a larger model for the top 50 candidates.
- Formatter pass: use Qwen3-0.6B again to emit strict JSON for the next system.
- Act & log: APIs, DB writes, Slack—always with structured payloads and trace IDs.
That loop is simple to test and cheap to run. And because Qwen3-0.6B handles the first and last mile, you decouple the expensive parts from the user’s clock.
Benchmarks that actually matter (and what to ignore)
Leaderboard screenshots are great for slides, but production wins come from the boring metrics: p50/p95 latency, error budget, cache hit rate, tail tolerance under load. In our experience, Qwen3-0.6B gives you room to maneuver on all of them by keeping the easy work off your big models.
| Dimension | Large Model | Qwen3-0.6B | Takeaway |
|---|---|---|---|
| Latency | High | Low | Small gates keep p95 in budget. |
| Cost | High | Low | Cheap enough to fan out widely. |
| Energy | High | Low | Edge/CPU/NPU friendly. |
| Use-case spread | Fewer, deeper | Many, narrower | Win by quantity, not just ceiling. |
Put differently: make Qwen3-0.6B your flavor enhancer. It won’t be the main course, but it makes the whole meal better.
Cost math your CFO will actually appreciate
Spend is not just “tokens × price.” It includes cloud egress, retries, cold starts, idle GPU burn, and ops time. By moving safety checks, formatting, and query polish to Qwen3-0.6B, you’re chopping off the thorniest bits of waste:
- Fewer retries: cleaned queries and strict JSON reduce failed actions.
- Smaller contexts: rewrite before recall so you don’t drag megabytes into prompts.
- Cheaper fallbacks: when the big model hiccups, Qwen3-0.6B can still carry the ball.
Deployment patterns: from laptops to edge boxes (and your phone)
One joy of Qwen3-0.6B is how portable it is. You can run it on a developer laptop for CI checks, a compact edge server in a store, or an NPU-equipped phone. A few patterns we like:
- CPU micro-service: a tiny container exposing a moderation + rewrite endpoint. Perfect for staging and bursty traffic.
- NPU on device: ship a quantized build for privacy-first features. Sync logs later.
- GPU batched worker: when volume spikes, batch small tasks together for efficiency.
If you want to go deeper on the tooling side, the Transformers docs are a goldmine for adapters and inference tricks, and NVIDIA’s write-ups on TensorRT-LLM acceleration are great for squeezing out throughput.
Observability & guardrails you should bake in from day one
Small models make it easier to scale observability because you can afford to measure everything. With Qwen3-0.6B gates in place, store a tight ledger:
- Prompt hash, output hash, model version, latency, tokens.
- Decision traces (allow/deny + reasons) from the safety gate.
- Strict schema validation results before any side-effects.
- Routable IDs so you can replay or roll back safely.
// Tiny validator edge function export function validate(json, schema) { const errors = ajv(schema).validate(json); return { ok: errors.length === 0, errors }; } With those guardrails, Qwen3-0.6B becomes a reliability feature, not just an ML component.
Personal anecdote: the night a “small” model saved a big launch
We were shipping a summer promo and the recommender started sending novelty items to people who only buy staples. Not a bug exactly—just fuzzy intent. I slipped a quick Qwen3-0.6B rewrite + light scorer before the recall step. Ten minutes later the dashboard showed normal CTR and lower refunds. That was the night I stopped underestimating small models.
FAQ: what Qwen3-0.6B can (and shouldn’t) do
Can it replace my big model?
No—and it doesn’t have to. Qwen3-0.6B is best as a guard, formatter, and planner that feeds larger models cleaner inputs and smaller contexts.
How do I tune it without a cluster?
Use LoRA/QLoRA and a few thousand curated samples. You’ll get reliable boosts on classification, safety, formatting, and light reasoning without breaking the bank.
What about hallucinations?
Keep it on narrow, structured tasks. For open-ended reasoning, let the heavy model take the wheel, but still use Qwen3-0.6B to shape inputs/outputs.
Bottom line: the “three lows, one high” formula
- Low latency → users feel it.
- Low cost → finance loves it.
- Low energy → greener by default.
- High coverage of small jobs → more wins, everywhere.
Make Qwen3-0.6B your seasoning. It won’t headline your roadmap, but it will make almost every feature taste better.