Self-hosted LLM projects feel glamorous on slide decks and downright messy in a closet at the back of an office. This guide is for the closet. I’m gonna give you the parts that break, the moves that actually help, and the gritty details teams forget until a pager goes off. I’ve stood in that closet—dust filter in one hand, clamp meter in the other—trying to shave 80 ms off a reply that must feel instant.
A quick personal anecdote. Last winter I was helping a scrappy retail team bring a self-hosted LLM online for in‑store product Q&A. We had a friendly model, neat prompts, and a cute kiosk. Day one, lunch rush hit. The queue spiked, the GPU thermaled, the vector store vacuumed the disk, and answers dragged. We didn’t buy new hardware. We fixed airflow, pinned quantization, pre‑tokenized common starters, and stopped the vector DB from fighting writes at noon. The kiosk felt snappy minutes later, not weeks. That’s the energy you’ll find here—no fluff, just the field notes.
1) Why a Self‑Hosted LLM Instead of “Just Use the API”
Three reasons keep coming up: latency, privacy, and spend. When your assistant is part of checkout, support, or ops tooling, every round trip to a remote API hurts the feel. Sensitive content—contracts, cameras, customer notes—belongs on your own disks. And when usage stays high all week, a healthy one‑time build plus predictable kWh often beats open‑ended per‑token bills.
Does cloud still matter? Absolutely. But a self-hosted LLM lets you keep the hot path close, while cloud remains a great place for overflow and experimentation.
2) Define “Winning” Before You Buy Anything
- Latency target: 150–300 ms p95 for chat completions feels “instant enough” in kiosks and internal tools.
- Uptime: Be honest—9–5 weekdays or lights‑out 24×7? The latter changes cooling, UPS, and on‑call life.
- Data posture: What never leaves your LAN? Decide now—raw docs, embeddings, logs, or all three.
- Budget window: Capex (chassis, GPUs, NVMe) + opex (power, cooling, people). Spend on predictability.
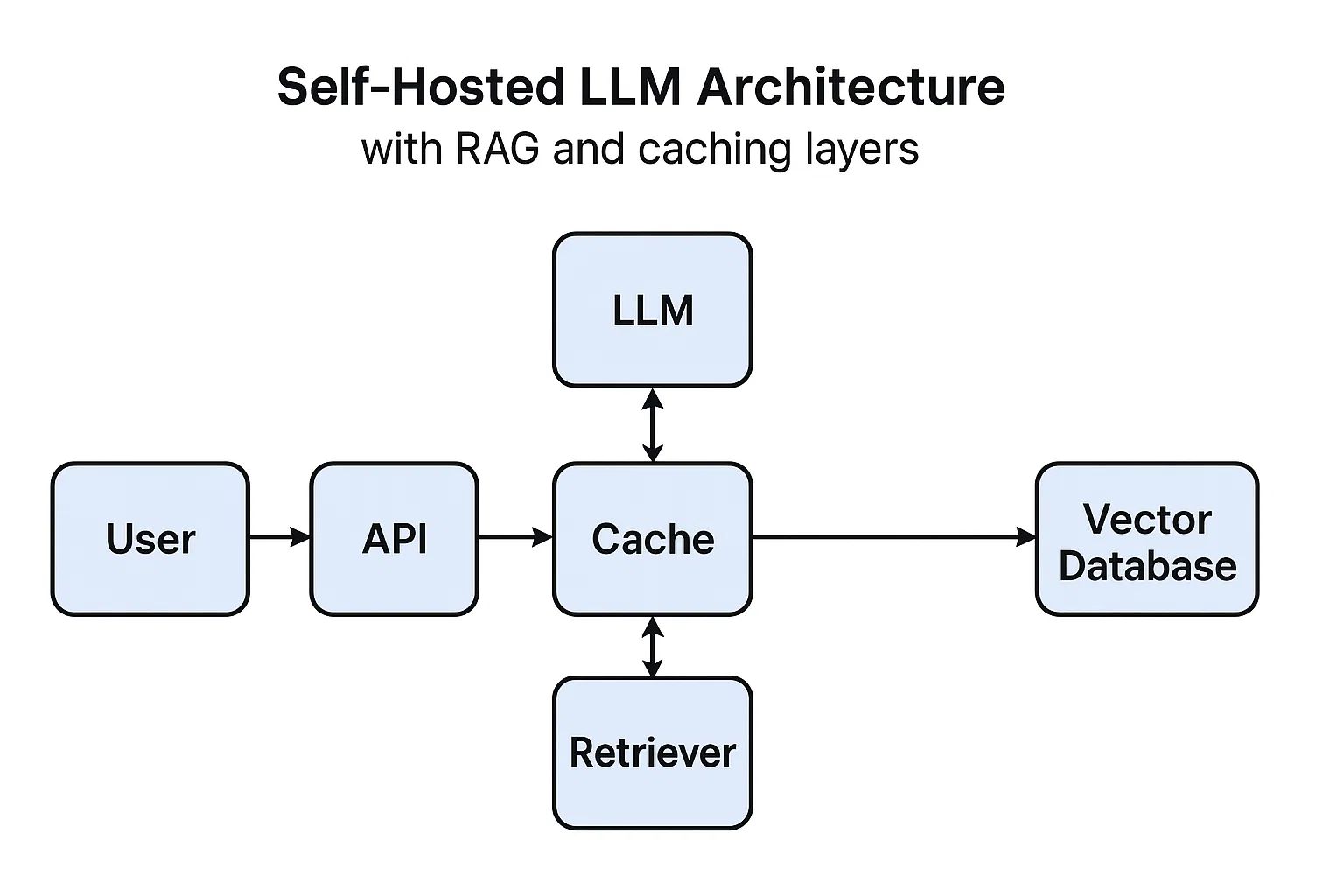
3) Self‑Hosted LLM Architecture: The Small, Honest Blueprint
Start with a single node that you can explain on a sticky note: ingress → preprocessor → chunker → embeddings → vector DB → model server → postprocessor → cache. That’s your backbone. Resist ten microservices. Fewer moving parts mean fewer 2 a.m. mysteries.
Map traffic. If half your queries start with the same ten words, pre‑tokenize those starters. Warm the cache. Tune batch sizes for your actual concurrency, not a benchmark screenshot.
4) Hardware: Buy Balance, Not Bragging Rights
A fast self-hosted LLM is a balanced machine. You want enough VRAM, enough PCIe lanes, enough NVMe, and just‑enough CPU to prepare tokens without turning midnight into a slideshow.
- CPU: Fewer sockets, more lanes. Practical 16–32 cores, strong AVX/AMX for tokenization and post‑processing.
- RAM: 128–256 GB for comfort; more if you run heavy embeddings, ETL, or concurrent RAG jobs.
- Storage: NVMe tiers: scratch (short‑lived), primary (weights and indexes), and bulk (archives and snapshots).
- Network: Dual 10/25G for east‑west copies and management. Segmented BMC on a management VLAN.
When you’re ready to go deeper on racks, thermals, and p99 power math, this longform is worth bookmarking: AI Server: 31 Brutally Practical, Game‑Changing Lessons.
5) VRAM Math You Can Explain to Finance
Rough sizing beats vibes. Parameter count × bytes/weight + KV cache + activations = the VRAM you actually need. Quantization helps, but the KV cache is where sessions quietly you‑turn your hopes.
| Model Size | Quantization | Weights (approx) | KV Cache / User (2k tok) | Notes |
|---|---|---|---|---|
| 3B | Q4_K_M | ~2–3 GB | ~0.6–0.8 GB | Great for classification and routing |
| 7B | Q4_K_M | ~4–5 GB | ~1.0–1.5 GB | Solid help‑desk / form‑filler |
| 13B | Q5_K_M | ~10–12 GB | ~2.0–2.5 GB | Better reasoning, latency climbs |
| 70B | INT8 | ~80–100 GB | ~8–12 GB | Shard or buy bigger cards |
6) Picking Models: Start Smaller Than Your Ego
Most teams overshoot. A well‑tuned 3–7B with clean prompts and light RAG is shockingly capable for internal tools. You’ll upgrade later; your users need speed now. Keep a “big brain” on standby for tricky flows and route there only when needed.
Use clear, typed outputs (think JSON schemas). A tidy 7B that returns valid objects beats a 70B that tells stories.
7) Quantization Without Regret
Quantize weights thoughtfully, then pilot with real documents. Start with GGUF Q4 or Q5 on mid‑sized models and walk up to INT8 where throughput > microscopic accuracy wiggles. Keep a floating‑point baseline around for tricky corner cases.
For practical tooling, vLLM, llama.cpp, and vLLM provide clean knobs for quantization and batching.
8) Serving: A Minimal Stack That Ships
A simple containerized service with a health check and clear metrics beats a fancy mesh that nobody can debug. Whether you lean on vLLM, llama.cpp, or Ollama, pin versions and test rolling restarts under load.
# docker-compose.yaml (baseline)
services:
llm:
image: vllm/vllm-openai:latest
container_name: llm
restart: unless-stopped
runtime: nvidia
environment:
- VLLM_ATTENTION_BACKEND=FLASH_ATTN
ports:
- "8000:8000"
volumes:
- ./weights:/weights
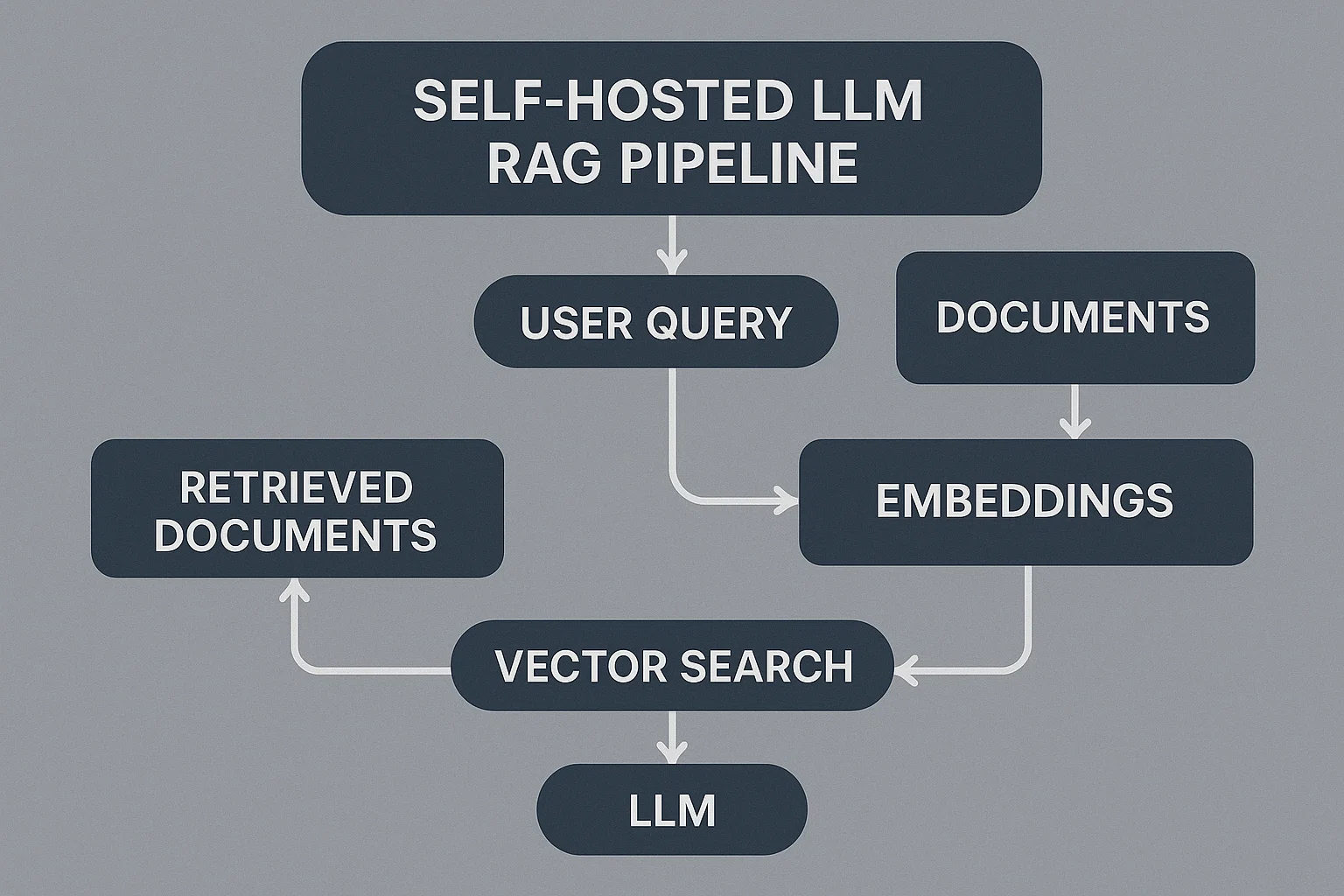
command: ["--model","/weights/model.gguf","--gpu-memory-utilization","0.90"]9) The RAG Backbone: It’s 80% of Perceived “Smart”
Chunking, embedding, and retrieval decide whether your self-hosted LLM feels like a helpful colleague or a distracted intern. Keep chunks small (200–400 tokens), store clean IDs, and normalize text consistently (case, punctuation, Unicode). Add a “last updated” field per document so your UI can show context freshness.
# quick-and-clean embedding insert (Python + FAISS-like interface)
ids, vectors = [], []
for doc_id, chunk in chunker(docs):
vec = embed(chunk)
ids.append(doc_id)
vectors.append(vec)
index.add_with_ids(np.array(vectors).astype('float32'), np.array(ids))10) Vector Stores: Pick the One You Can Operate at 2 a.m.
FAISS is fantastic when you want speed and simplicity; pgvector is lovely when your team already knows Postgres. What matters: backups, observability, and query latencies under load. Whichever you choose, rehearse restores.
11) Prompts That Produce JSON—Not Poetry
Push your self-hosted LLM toward structured output. Humans can read prose; your pipeline needs validated objects. Keep a short schema in the prompt and reject replies that don’t parse. It’s boring. It works.
{
"type": "object",
"required": ["summary","action_items"],
"properties": {
"summary": {"type": "string"},
"action_items": {"type": "array","items":{"type":"string"}}
}
}12) Concurrency, Batching, and the “Feels Fast” Budget
Throughput isn’t tokens per second; throughput is how many people feel heard without waiting. Shape queues, cap context, and pre‑tokenize common prefixes. Keep batch sizes modest if tail latencies wobble. Measure p95, not the best screenshot of your life.
13) Observability: Evidence or It Didn’t Happen
Dashboards should answer three questions: Are we up? Are we fast? Are we melting? Expose tokens/sec, queue depth, GPU temperature, power draw, and vector store latency. Alert on thermal throttle and NVMe queue depth spikes.
14) Storage Tiers That Don’t Bite You
Put weights on a fast NVMe tier with a filesystem you understand (XFS or ZFS). Use a scratch drive for temp files so you don’t fill the tier holding your models. Snapshots are cheap insurance; restore drills are the real test.
15) Network: Don’t Starve the Box
Even a single node benefits from clean NIC drivers, jumbo frames only where you’ve validated the path, and a tidy management VLAN. Packet loss during embeddings writes feels like “the model got dumber.” It didn’t. Your network just sneezed.
16) Security: Make the Blast Radius Boring
Run as non‑root, segment services, lock down model directories read‑only in prod, and rotate creds on a real schedule. If you want a straight‑talking hardening primer shaped for 2025 realities, this piece is a keeper: Zero Trust Server Security: A 2025 Field Guide.
17) Agents: When to Add Them—and When to Say No
Agents shine when tasks chain: search → summarize → act → verify. They stumble when prompts are vague or data is stale. Add guardrails: JSON everywhere, idempotent actions, and humans approve anything risky. For a production‑minded blueprint, read AI Agents for Developers: Practical Patterns for Production.
18) Local Dev: Practice Where You Play
Build and test locally with the same runtime you’ll ship. Your laptop becomes a rehearsal stage for the self-hosted LLM—same model, same tokenizer, same port. When the Wi‑Fi flakes, keep working. A solid walkthrough here: Claude Code Local LLM—run it entirely on your machine.
19) Self‑Hosted LLM Latency Budget (Be Honest)
| Segment | Target (ms) | Notes |
|---|---|---|
| Ingress & auth | 10–20 | Keep cookies small, avoid heavy middlewares |
| Preprocess & chunk | 10–30 | Cache common starters |
| Vector search | 20–40 | Warm indexes, watch P90 under load |
| Model decode | 80–180 | Batch carefully, stream early |
| Postprocess | 10–20 | Validate JSON, light grammar pass |
20) Streaming: Perception Hacking for Free
Start streaming tokens as soon as the model begins decoding. Users will forgive total time if the first word lands early. Just don’t break your JSON—stream prose, not the final structured part.
21) Cache Like You Mean It
Two caches: one for retrieval (top‑K answers for common queries) and one for completed responses by normalized prompt + user segment. Evict with LFU, not pure LRU—hot questions stay hot.
22) Guardrails: The “No Surprises” Zone
- Schema‑first prompts with hard validations.
- Allow‑lists for tools the model can call.
- Rate limits and circuit breakers per user and per route.
23) MLOps: Version the Boring Stuff
Version prompts, tokenizers, embeddings, and weights. Log the exact artifact IDs with each reply. “Latest” is not an ID. When someone shouts “it got worse yesterday,” you’ll know exactly what changed.
24) LoRA & Light Fine‑Tuning: Where It’s Worth It
Don’t fine‑tune for vanity. Do it when you have consistent, structured tasks and a clean dataset. Keep adapters small, evaluate like a skeptic, and roll back ruthlessly if p95 grows or error rates creep.
25) Data Hygiene: Ingest With Respect
Garbage in, confident garbage out. Normalize encodings, strip boilerplate, dedupe nearly‑identical docs, and label doc sources. Keep a quick “redaction pass” for sensitive fields before they ever hit embeddings.
26) Scheduling: Use a Queue Even on One Box
Give each route a priority. Kiosk traffic should trump batch summarization. Let low‑priority jobs back off when the room heats up. Your self-hosted LLM will feel smarter without changing a single weight.
27) KPIs That Matter (and the Tempting Ones That Don’t)
- Do track: p95 latency, tokens/sec per GPU, vector P90, invalid JSON rate, rollback rate.
- Don’t obsess over: average latency screenshots, single‑prompt wins, social‑media benchmarks.
28) Disaster Drills: Practice the Pain
Quarterly: restore your vector DB, replay a sampling of prompts, and verify outputs match known‑good hashes. Label the runbook with the last person who actually did it. If their name’s from last year, you’re overdue.
29) Self‑Hosted LLM Security: A Quick, Real Baseline
# UFW baseline
ufw default deny incoming
ufw default allow outgoing
ufw allow 22/tcp
ufw allow 8000/tcp # inference
ufw allow 9100/tcp # node exporter
ufw enableAdd mutual TLS for internal calls, rotate app tokens every 30 days, and keep model files immutable in production. Boring beats breached.
30) Ops Rituals That Save Weekends
- Change windows with rollback scripts you’ve tested.
- Warm caches before the morning rush.
- “Red team” a prompt weekly—try to break formatting and guardrails.
31) Cost Truths: You Pay Either Way
Capex buys you predictable capacity; opex sneaks up via power, cooling, and people. A quiet node that never throttles is cheaper than an “epic” build that reboots at 4 p.m. Measure, don’t guess.
32) Team Habits: Make It a Teammate, Not a Toy
Ship small, gather feedback, iterate. Tie prompts to runbooks. When the system answers, link to the documents it used so humans can trust it. Trust beats wow.
33) Rollouts: Blue‑Green Is Your Friend
Stand up a second instance with the new weights/prompt set, send 10% of traffic, watch metrics, and flip only when you like what you see. Keep your old instance warm for a day. Future‑you will thank present‑you.
34) When to Scale Out (Not Up)
If your p95 climbs with concurrency, add replicas before you chase a flagship card. Two mid‑tier GPUs often beat one giant when queries are short and independent.
35) Edge vs Core: Different Rooms, Same Discipline
Edge builds live near customers (dust, heat, curious hands); core builds live in cleaner rooms with fatter pipes. Either way, airflow, power budgeting, and tidy scheduling keep your self-hosted LLM honest. For a deep edge‑ops dive: Edge AI Server: 33 Field‑Tested Moves.
36) Developer Experience: Keep It Boring and Fast
Local dev containers. One‑command repro. Static configs. No magic. A predictable DX means more experiments and fewer “works on my machine” debates. If you’re building UI around your assistant, this design guide pairs nicely with sane APIs: UI Design Trends 2025.
37) Your First Production‑Ready “Hello World”
Glue the pieces with boring HTTP. Simple, observable, and easy to roll back. Don’t hide logic in a maze of plugins or middleware.
# minimal client — Python
import requests, json
resp = requests.post("http://llm.local:8000/v1/chat/completions", json={
"model": "local-7b-q5",
"messages": [{"role":"user","content":"Summarize: https://intranet/policy"}],
"stream": True
}, timeout=15)
for line in resp.iter_lines():
if line: print(line.decode())
A Short Reading List for the Doers
- Transformers documentation — pragmatic, constantly updated, and great for quick checks.
- vLLM — high‑throughput serving with sensible APIs.
- llama.cpp — tiny, fast, and a perfect fit for compact nodes.
Practical Checklist (Print This)
- Write down latency and privacy goals. No goals, no gear.
- Pick a model smaller than your ego. Measure with real docs.
- Quantize, then validate with humans. Keep a float baseline.
- Map chunks → embeddings → vector DB → model → cache.
- Expose metrics: p95, tokens/sec, vector P90, throttle flags.
- Protect the room: airflow, filters, UPS, and a label that says “don’t block this vent.”
- Rotate secrets. Read‑only weights. Non‑root processes.
- Blue‑green deploys; rehearse restores every quarter.

Final Thoughts
You don’t need a stadium full of GPUs to make a self-hosted LLM feel like a superpower. You need a tidy plan, honest measurements, and boring, repeatable moves. Start small. Stream early. Cache shamelessly. Protect the room. When it hums, scale with intention.
The closet doesn’t have to be scary. With the right checklist and a little stubbornness, your self-hosted LLM will feel fast, stay private, and quietly do its job while your team goes home on time.





